Suppose you need to find a web page containing a number, but you don’t know the exact number. Enter the Number Range operator. The number range operator looks like this: #..#.
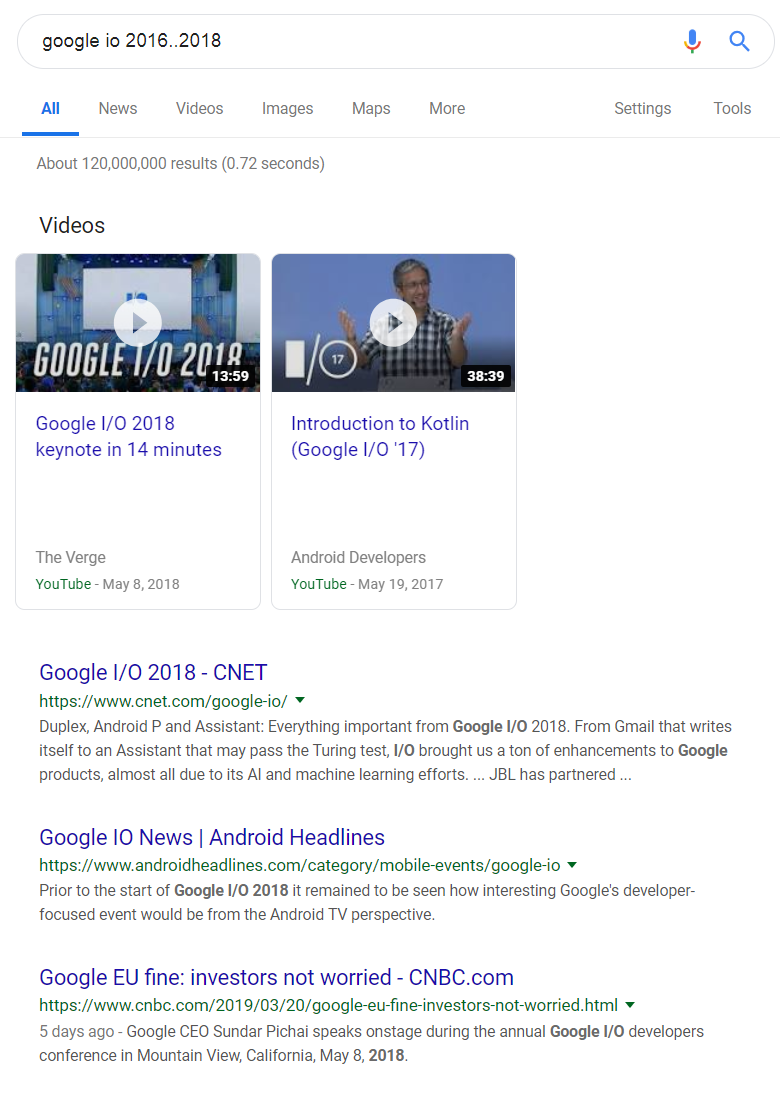
For example, if I wanted to search for content from the Google I/O conventions between Google I/O 2016 and Google I/O 2018, I could search for the following:
google io 2016..2018
As you can see from the videos top bar, I found content from Google IO 2018 (the keynote), and Google IO 2017 (Introduction to Kotlin).
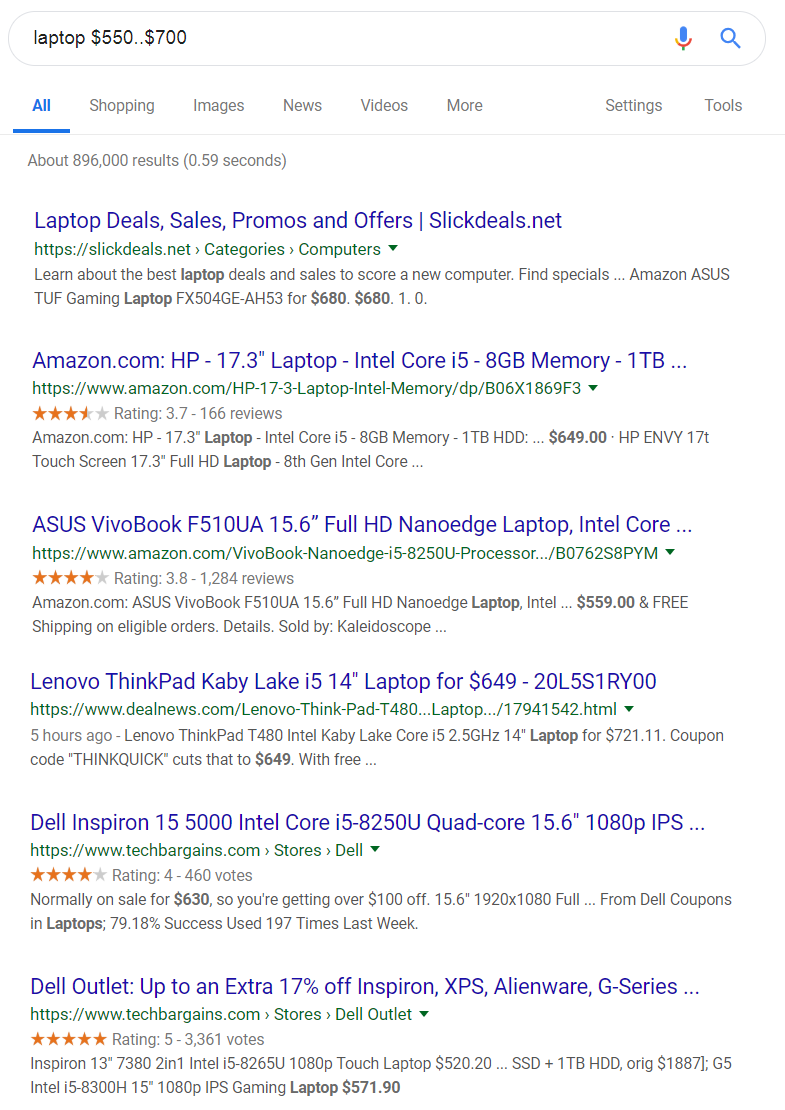
The number range operator works for prices as well. Suppose I wanted to buy a laptop, but my budget is only $550 to $700. Let’s try to find a laptop using Google search:
laptop $550..$700
As you can see from Google’s bolded text, I found multiple laptops within my price range of $550 to $700.
The rel=prev/next attributes were used to indicate paginated content to Google – for example, long forum threads broken up into multiple pages, slideshow-style articles, and so forth.
Google used to have a help page explaining the use of the attribute – it was located at https://support.google.com/webmasters/answer/1663744?hl=en , but is now deleted. You can see an older copy here:
The former help page discussing rel=prev/next. Click to expand.
This change doesn’t surprise me – it’s been clear for years now that Google is increasingly using ML/AI to “read” web pages and infer relationships between pages, instead of going by what the page says about itself. The information that it extracts can then be used to power knowledge panels on Google search pages.
Furthermore, I wouldn’t be surprised if Google finds pagination relationships to be less important than other signals. For example: if there’s a long forum thread discussing some controversial issue, every page of the forum thread is not equally important; perhaps Google wants to focus on only those pages with important information, or those that get linked to the most frequently.
Today’s Google doodle celebrates Seiichi Miyake, who invented paving slabs with tactile feedback, allowing the blind and visually impaired to navigate the world.
Here’s the Google home page with the doodle:
Here’s the doodle itself:
The Google doodle for March 18, 2019.
The Google doodle links to a search for Seiichi Miyake:
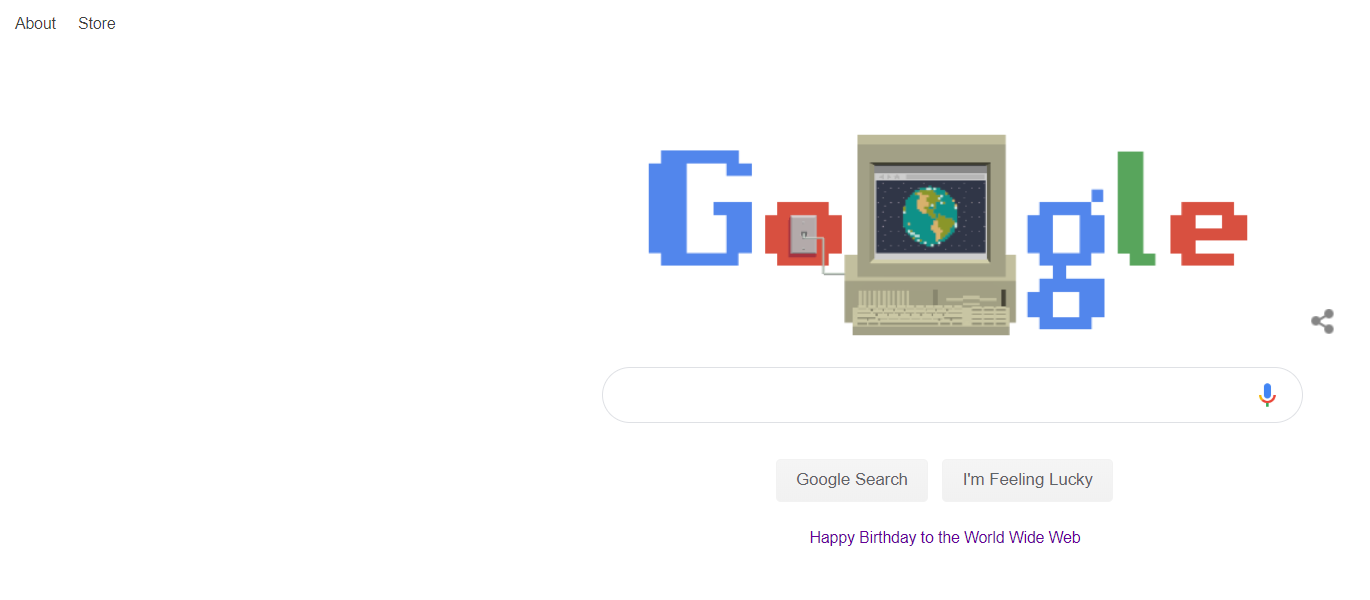
Today’s Google doodle celebrates the 30th anniversary of the world wide web. Here’s a screenshot of today’s Google front page:
Google front page for March 12, 2019.
Here’s the doodle itself:
The Google doodle for March 12, 2019.
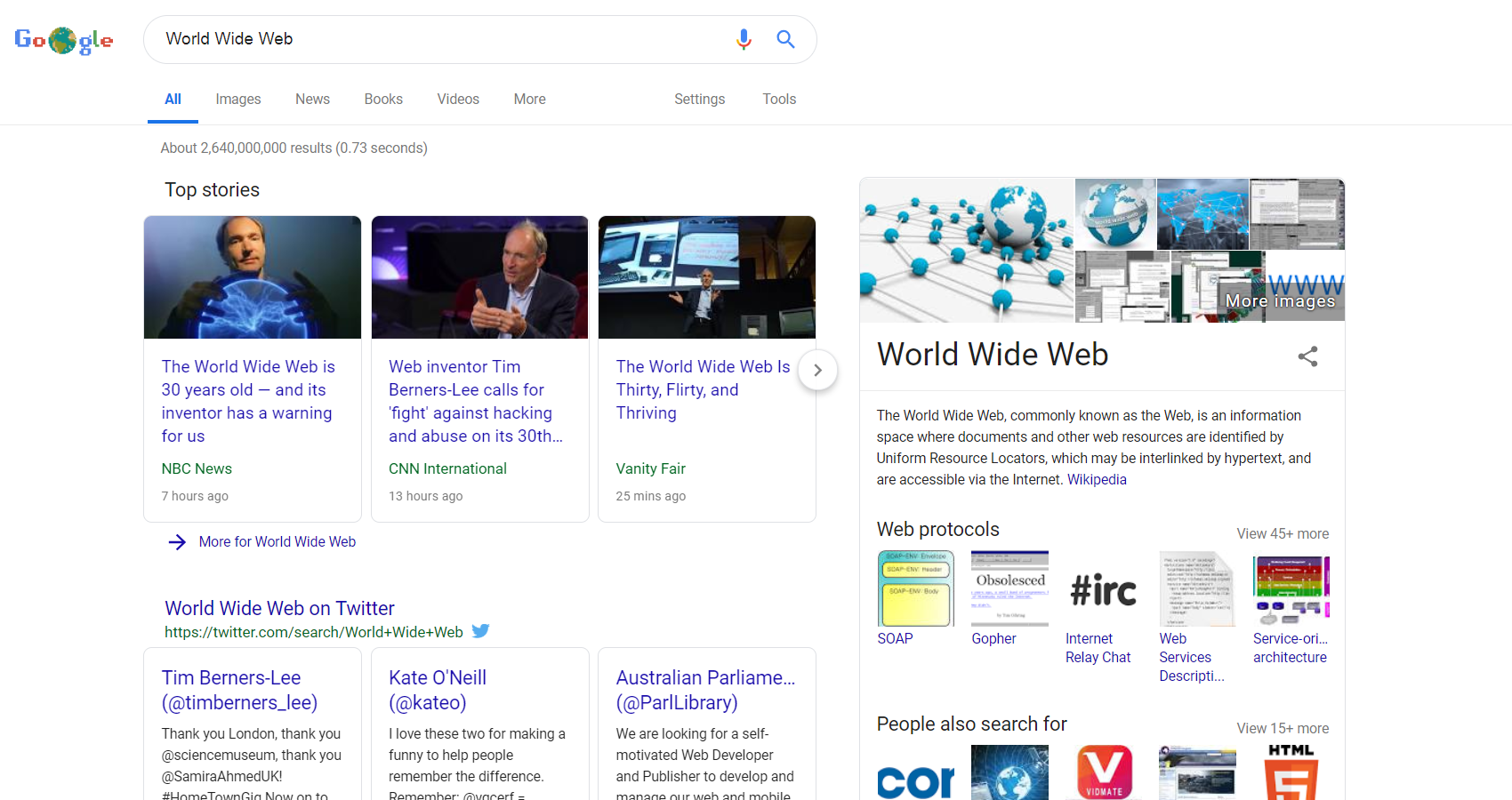
Clicking on the doodle performs a Google search for World Wide Web:
Clicking on the doodle Google search.
On the Google front page, clicking on the text Happy Birthday to the World Wide Web goes to a Google Arts & Culture page discussing the history of the Internet:
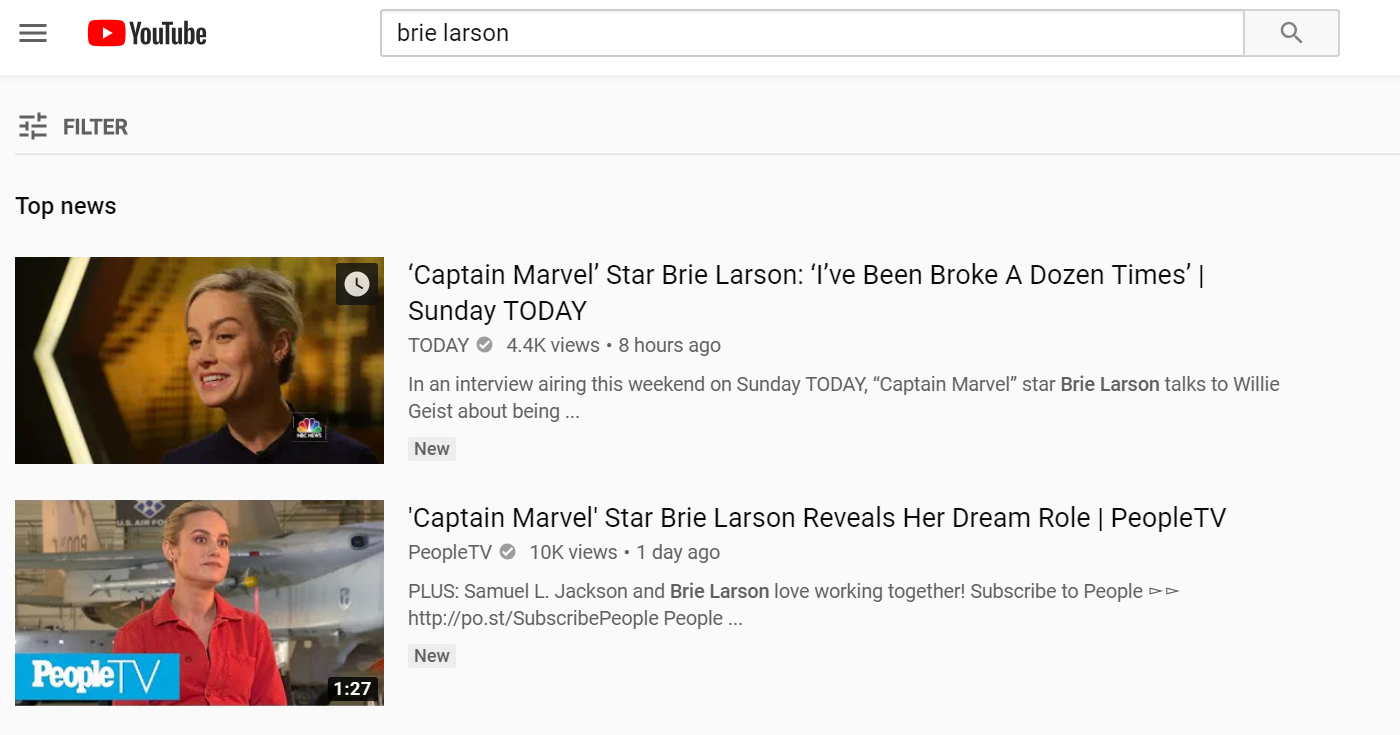
In short, YouTube searches for Brie Larson were initially returning videos about boycotting the movie Captain Marvel. By tagging Larson as a news item, the search results immediately changed to reflect videos from authoritative news services: ABC, CBS, Entertainment Tonight, and so forth. This is a useful function for most people searching, as most users will be looking for late night interviews, news media reports, and so forth.
A search for Brie Larson on YouTube returns videos from news services – note the Top news notice on the top of the image.
As this article demonstrates, search context can be very important. To fully learn about a topic, it’s vitally important to search Google, review the results, then make more searches that are informed by your previous searches. Let’s say you’re a journalist, and want to write about Brie Larson. You’d start out with a general Google and YouTube search about Larson. Then by reviewing the search results (at least the first 2-3 pages of results) you’d learn that there was controversy over Larson playing Captain Marvel. Then you could search for Brie Larson Captain Marvel. Then Brie Larson controversy.
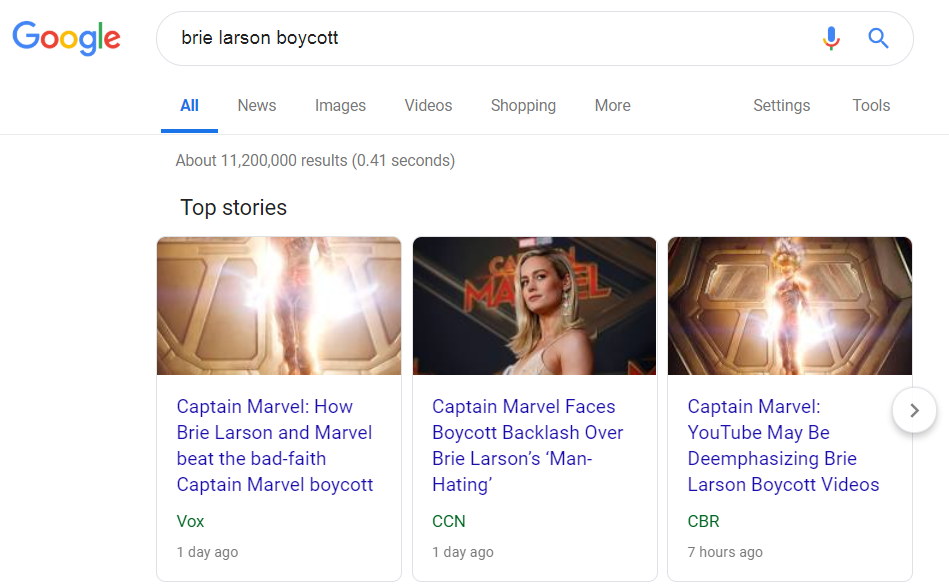
Possibly you might dig a bit deeper and search for Brie Larson boycott. After you’ve exhausted that route, follow other discussion threads: for example, searching for Brie Larson fans, or Captain Marvel box office numbers.
A search for Brie Larson boycott reveals further information for an aspiring journalist. Why is there a boycott? Further Google searching would help.
There are numerous ways that a good journalist could dig up even more information about this issue – for example, why not use Google’s date searching feature to exclude recent news reports and only search earlier postings?
Googling current-news topics can be difficult, as you’ll see many current news items pop up on your results. With intelligent Googling, you can extract useful knowledge about almost anything.
The AROUND(#) search operator is one of my favorite, and frankly underrated, search functions. It is a distance operator between two words; in other words, it searches for web pages that have two words together, with no more than # of words separating them.
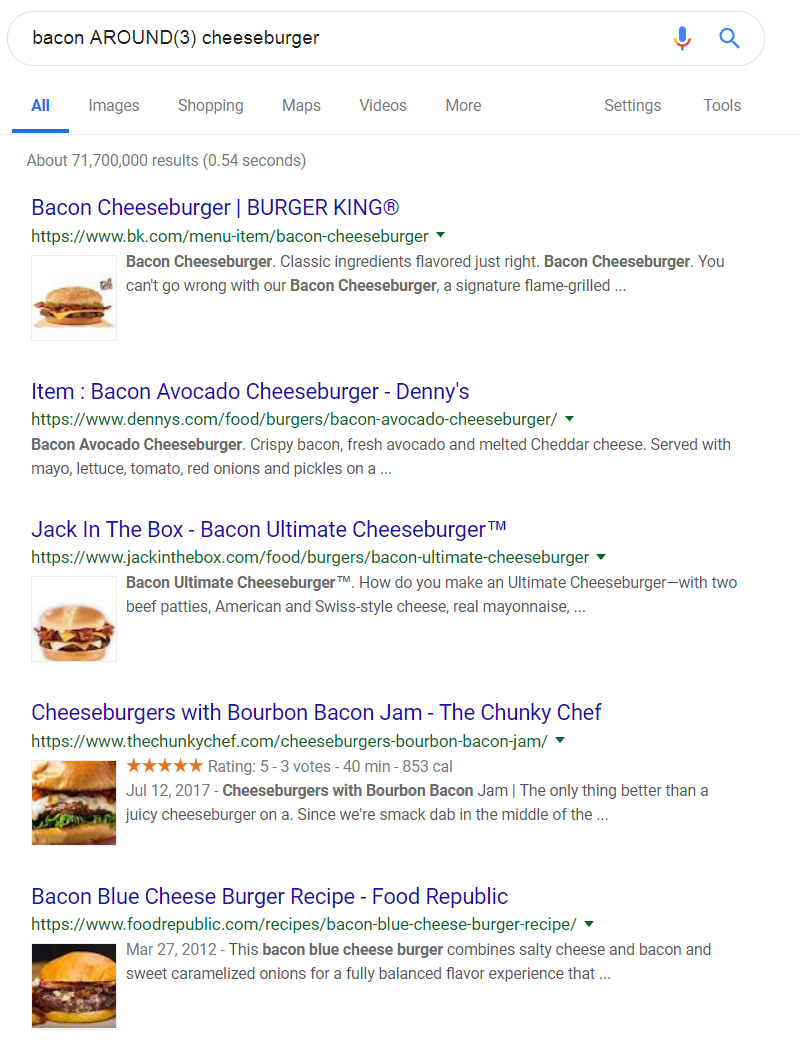
Here’s a simple example. Suppose I tried searching for bacon AROUND(3) cheeseburger.
bacon AROUND(3) cheeseburger
Google returns the expected bacon cheeseburger results, but there are also some interesting, unexpected results. The second result is for a bacon avocado cheeseburger (1 word – avocado – separating our search terms of bacon and cheeseburger). The third result is for a bacon ultimate cheeseburger (again, 1 word separating bacon and cheeseburger). The fourth result is for cheeseburgers with bourbon bacon (2 words – with bourbon – separating our search terms).
Use the operator whenever you need to find two words closely associated with each other, but possibly modified by other words. Try not to use a high # with AROUND(#) – I would suggest no more than 5 unless there’s a really good reason for a greater distance.
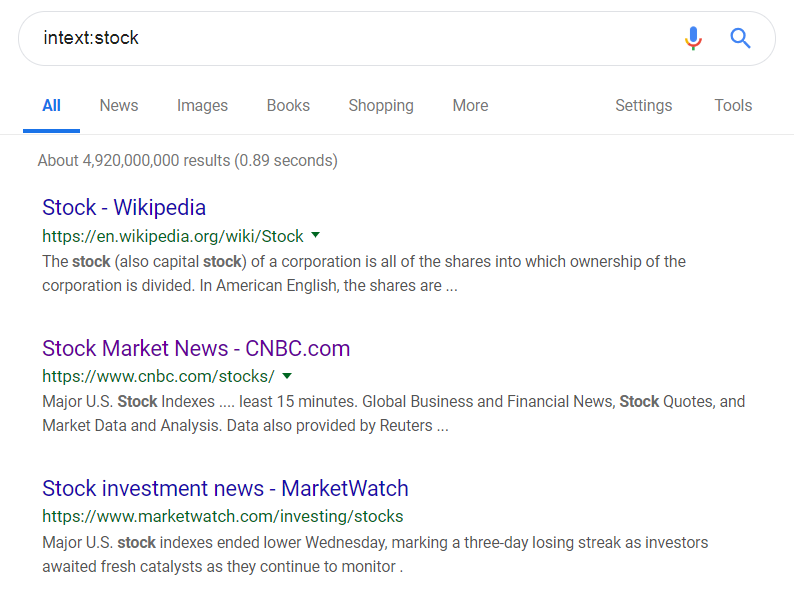
Among the less useful of operators are the intext: and allintext: search operators. As the title says, these operators require that the given word(s) show up in the content of a web page. For example, if you searched for intext:stock (no space between intext: and the searched keyword), the returned web pages would have the word stock as part of the web page:
intext:stock
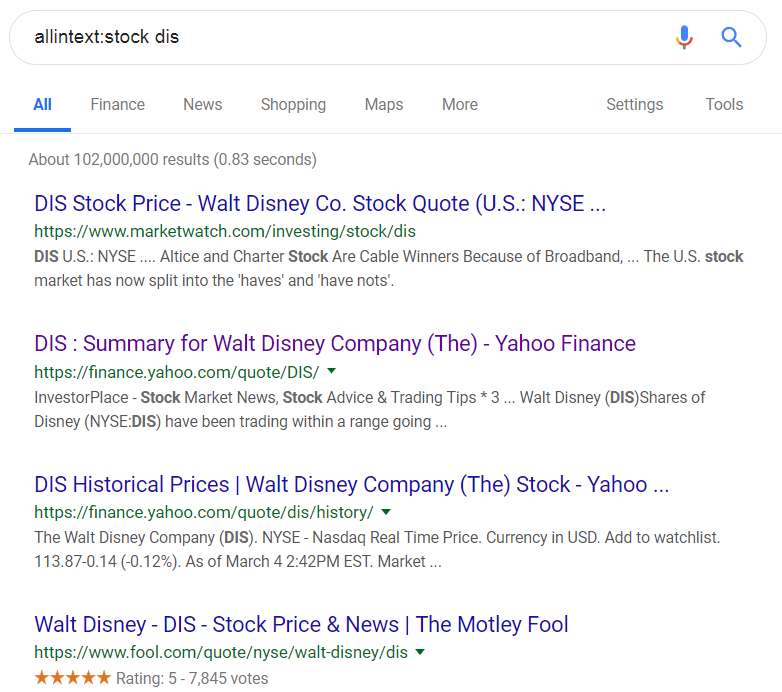
Similarly, if you searched for allintext:stock dis, you would get web pages with the words stock and dis within their text content:
allintext:stock dis
While these operators are important to remember, they’re not as useful as their intitle/allintitle/inurl/allinurl counterparts. In the vast majority of cases, skipping the intext: search function and searching on the same key words would result in the same, or largely the same, search results as using the operators.
An URL is an Uniform Resource Locator – it is the https://… gobbledegook on the top of your web browser. It’s also frequently called the web address, or just address. I will be using the words URL and address interchangeably, and you can as well.
The inurl: and allinurl: search operators search for specific words in web page URLs. These operators work best when you’re searching for product pages, or blog entries.
A good example would be to look at an Amazon product page; here’s the URL to order an Amazon gift card:
As you can see, Amazon describes the product – an Amazon gift card – in the URL itself: Amazon-Amazon-com-eGift-Cards. You’ll see this design frequently in online stores, blogs, and so forth: it helps optimize the site for search engines such as Google.
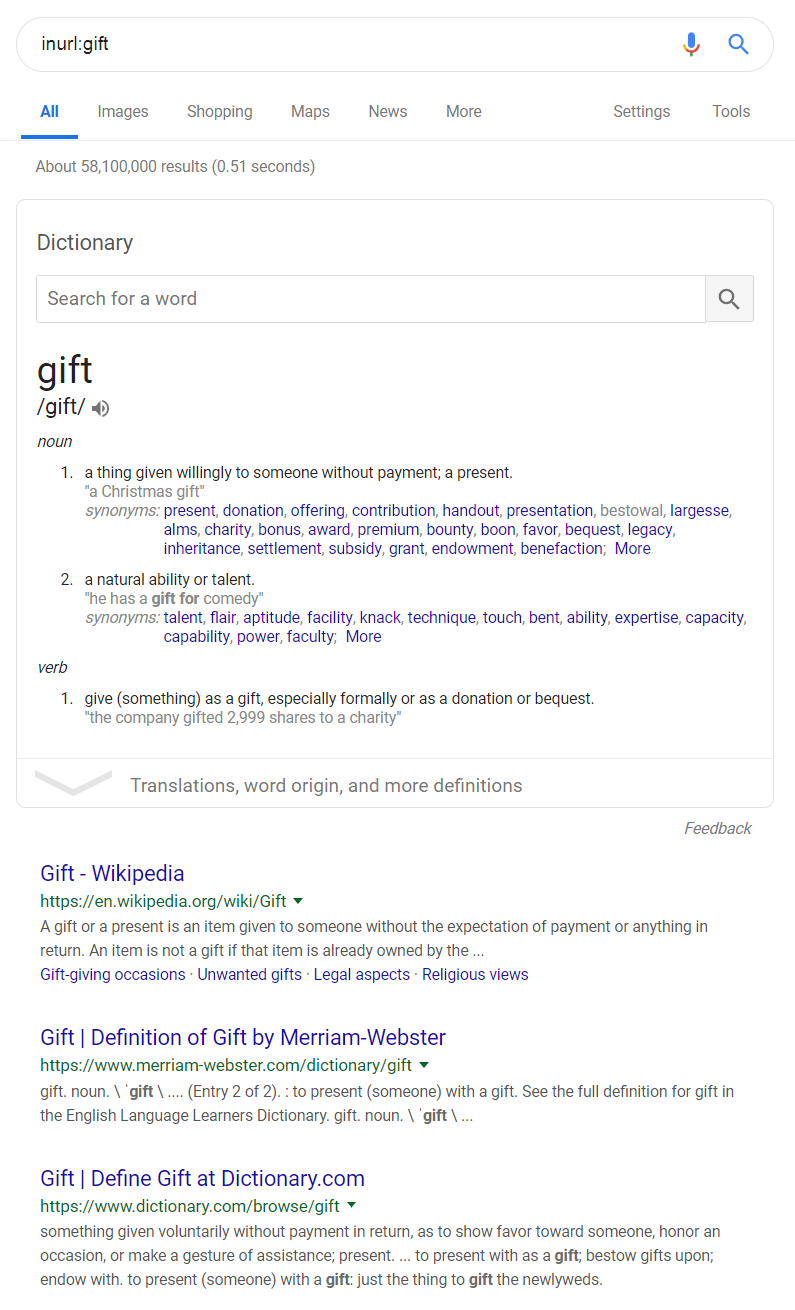
Suppose you wanted to search for gifts on Google. You might start out by searching for the following:
inurl:gift
That works – as you can see, all the URLs (green text) have the word gift in them. But the links aren’t useful: I wanted gift card information, not just general information about the word gift.
In this case, I can turn to the allinurl: operator, which will require that all the words I list should be in the URL. Let’s try:
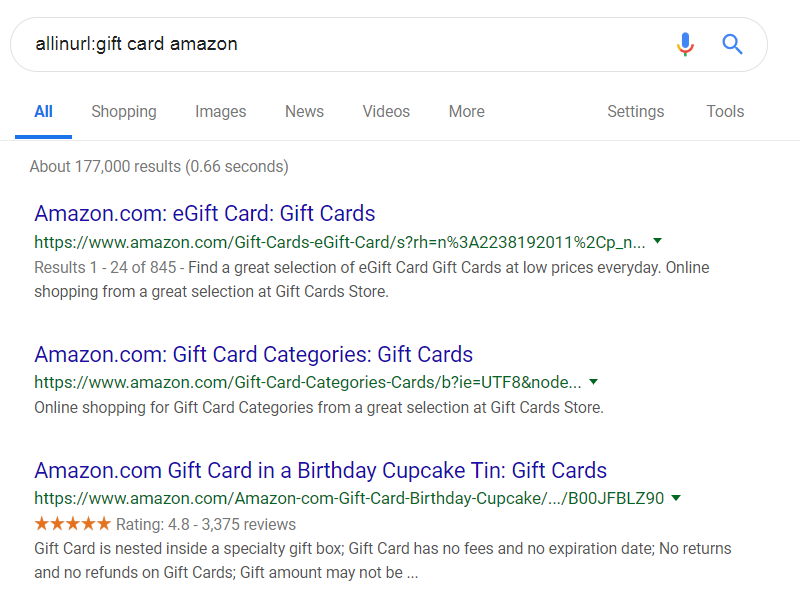
allinurl:gift card amazon
Now that search was useful – all of these URLs (green text) contain the words amazon, gift and card.
In general, while the inurl: and allinurl: operators are incredibly useful, I would recommend trying the intitle and allintitle: operators first. Web page titles tend to be more detailed and have more space than URL addresses. inurl and allinurl are more useful for the times where you’ve forgotten a certain web page URL – the address is just on the tip of your tongue, but you can remember fragments of it – inurl and allinurl can help you reconstruct it.