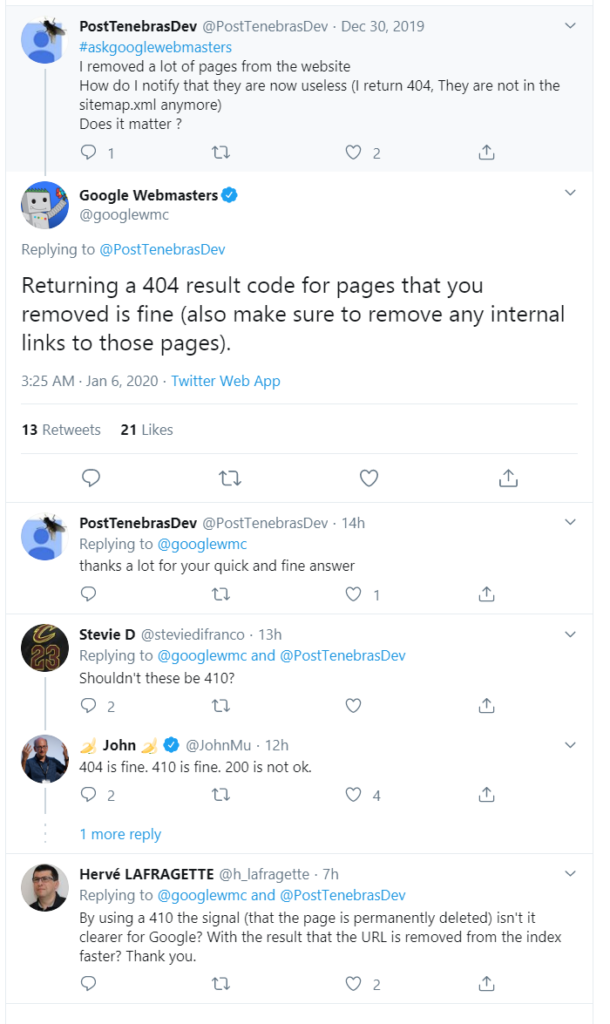
Lately we’ve seen some aggressive moves by Microsoft to pick up developer mind-share. The purchase of GitHub was the opening salvo, but Microsoft made a number of smaller moves recently as well: private repositories available for free on GitHub (previously you needed a student or paid account to have private repos), the acquisition of NPM (Javascript package manager and registrar), and GitHub Actions: a way to automate developer workflows – similar to a developer focused version of IFTTT/Zapier. Part of the new GitHub Actions makes it easier and faster to deploy code on Microsoft Azure.
Recently GitHub announced a huge drop of new features, the most important of which is Codespaces (an online IDE) and Discussions (a place to host community discussions). It’s clear to everyone that Microsoft is playing the long game in its war against Amazon Web Services: Microsoft is buying up developer mindshare, making it easier and faster to discuss, manage, and deploy applications on Microsoft services.
This leaves Google’s cloud platform in a difficult bind: how to compete against all these offerings? AWS is by far the market leader in the cloud game, with Microsoft in a strong 2nd place position and having strong Enterprise-size deployment credentials, plus increasing ownership of the development process. We’re beginning to see Google’s counter moves: recently they announced the release of a code editor within Cloud Shell. Here’s a screenshot as of today:
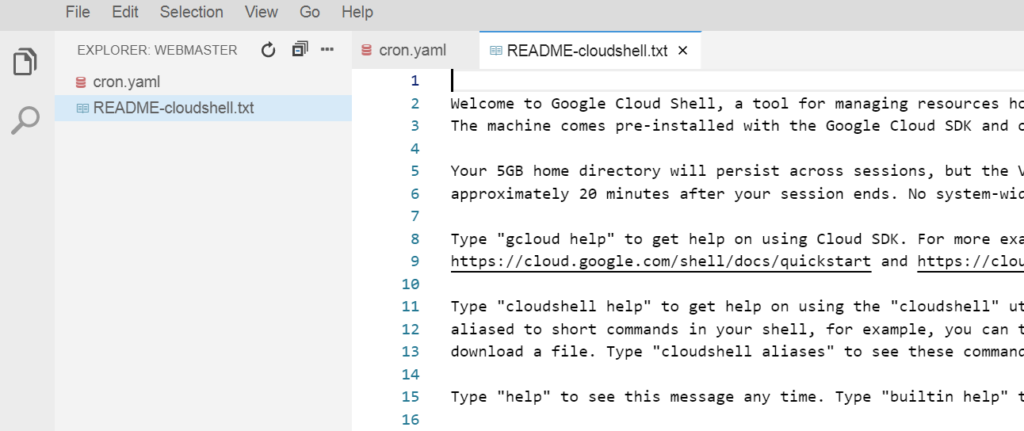
The bottom line is, Google Cloud needs to start opening up its checkbook if they want to compete with the options Microsoft and Amazon are developing/purchasing. Here’s a couple of companies I think Google should seriously consider purchasing:
- GitLab – GitLab is the perfect counter to Microsoft’s purchase of GitHub; GitLab includes the social coding aspect of GitHub, plus automated integration tools to compete with GitHub Actions
- An online IDE – There are a number of online IDEs available. I’ve been trying out a number of them and personally, I quite like GitPod.
- AI Services – Google needs something to differentiate its cloud platform compared to Microsoft Azure and AWS. An interesting play would be to lead the burgeoning AI industry. There are a number of players in this space, but a good starting acquisition would be Diffbot – it supplies APIs for structured extraction of text from a webpage and understanding context.
Some other acquisitions that I think make sense, especially in light of the current economic troubles driving down valuations:
- A note service to enhance GSuite. Google Keep exists, but it’s not as advanced as Evernote.
With a $1 billion valuation, Evernote may be too expensive to purchase, but there are a number of smaller competitors that still provide a great note-taking experience. A good example would be Notion. - AirTable. I’m surprised that nobody has acquired AirTable yet – it’s a marvelous new take on how spreadsheets and databases can be visualized.
- Automation tooling. Services such as IFTTT, Zapier, Integromat, Automate.io are the “glue” that can connect disparate services together. For instance, you can configure a new WordPress post to be saved to Google Drive/Dropbox – or any of hundreds of different web services.
A purchase of IFTTT or similar service immediately buys integration into many different web services, plus allows a deeper integration into Google products. Imagine making it easier to share your favorite YouTube clip to any social media you have.