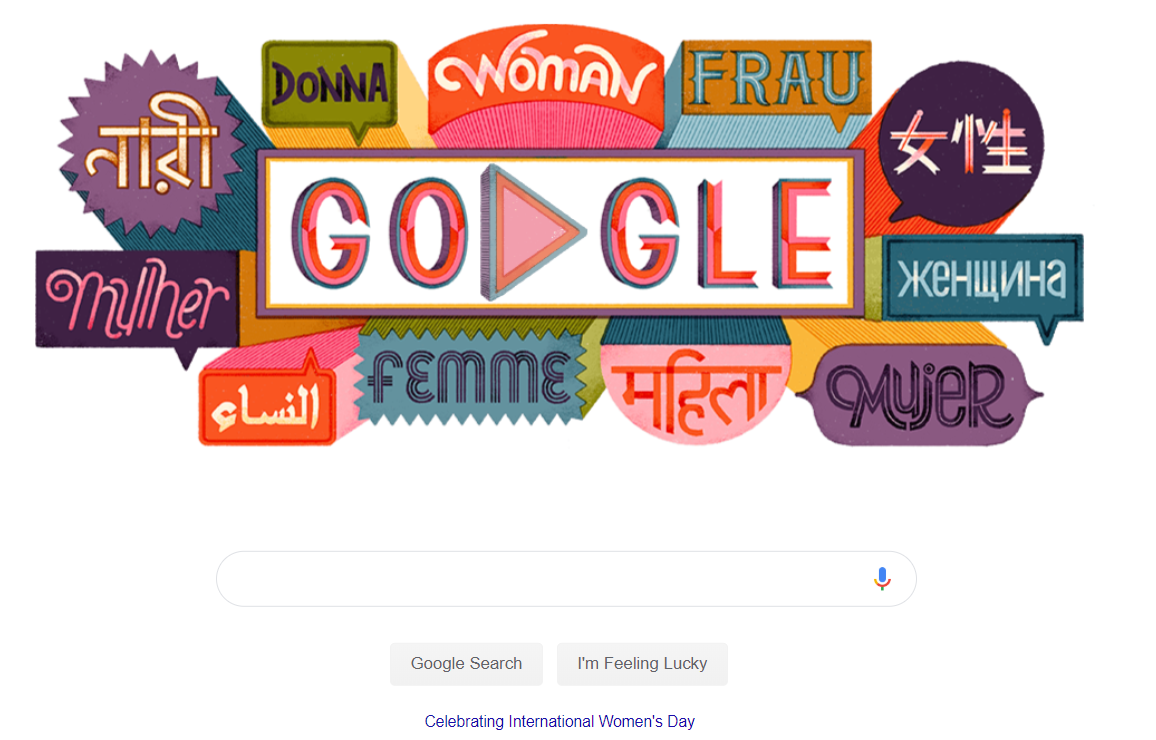
Today, March 8 2019, Google celebrates International Women’s Day with a doodle. Here’s how the doodle looks like on the Google home page:
Clicking on the doodle makes it expand:
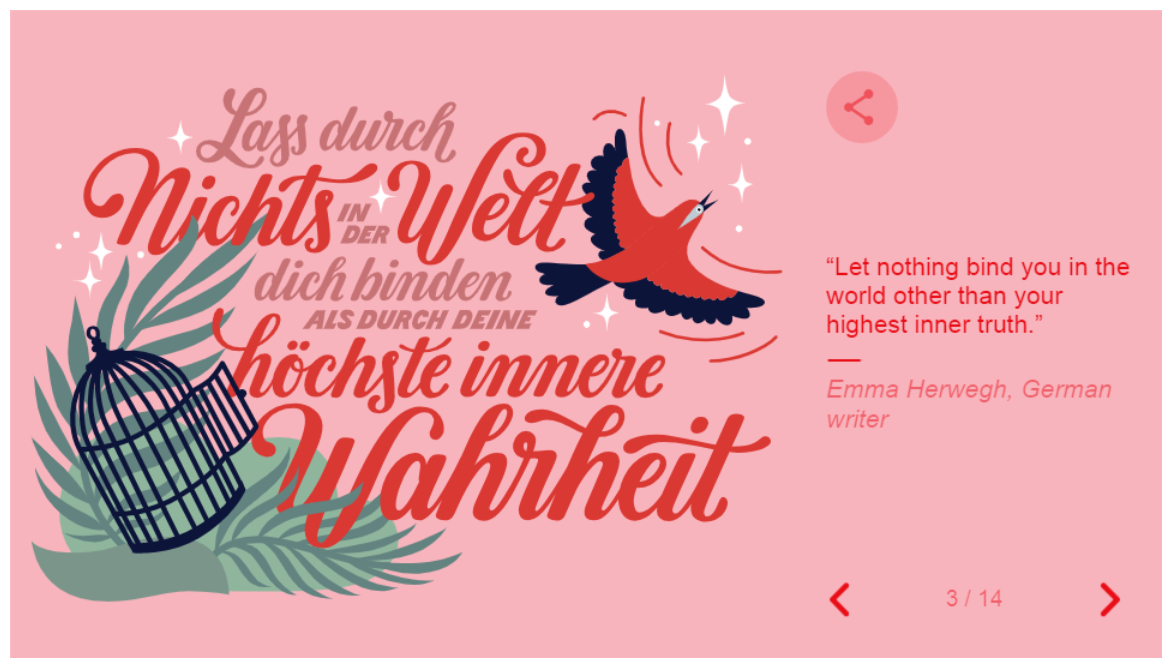
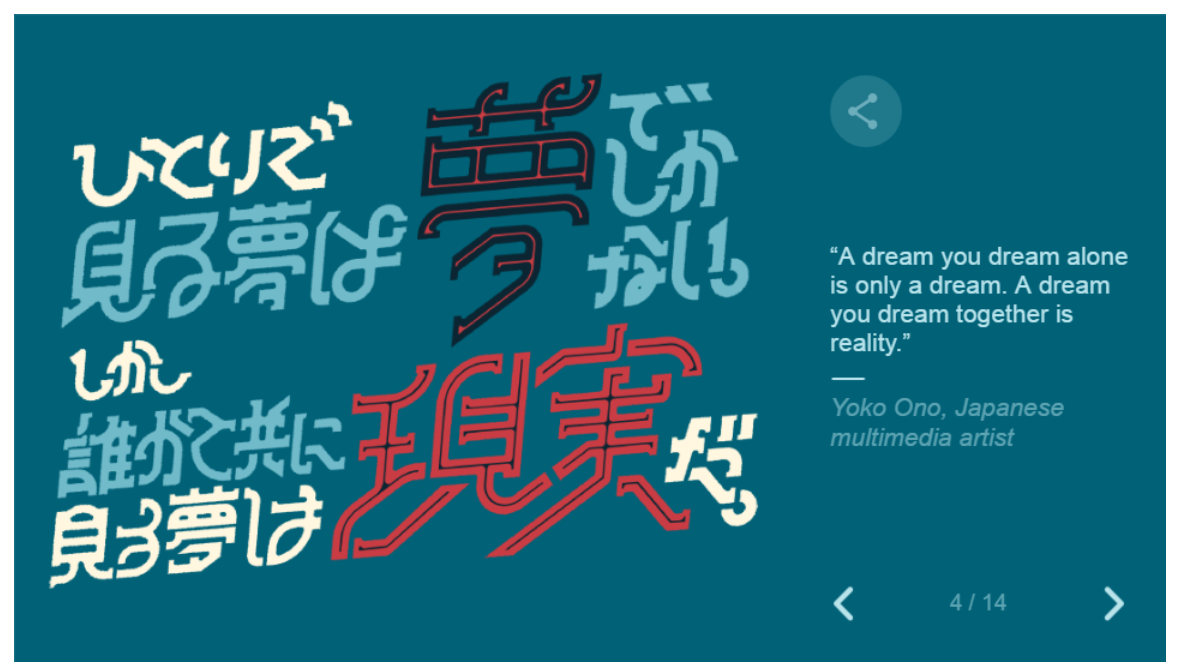
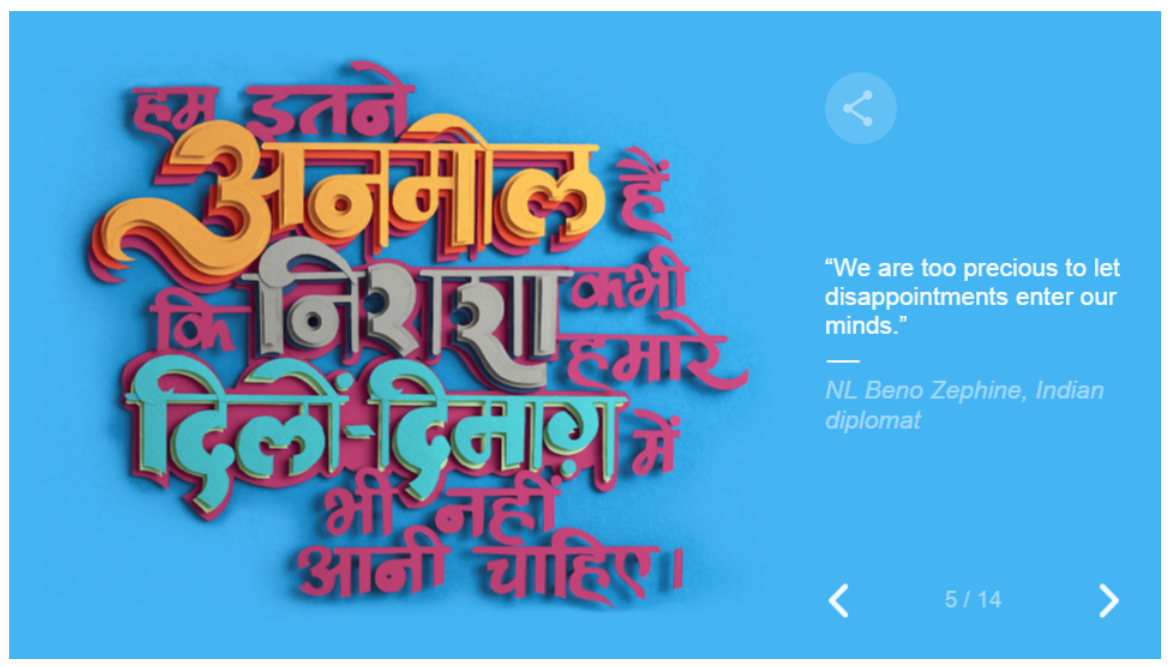
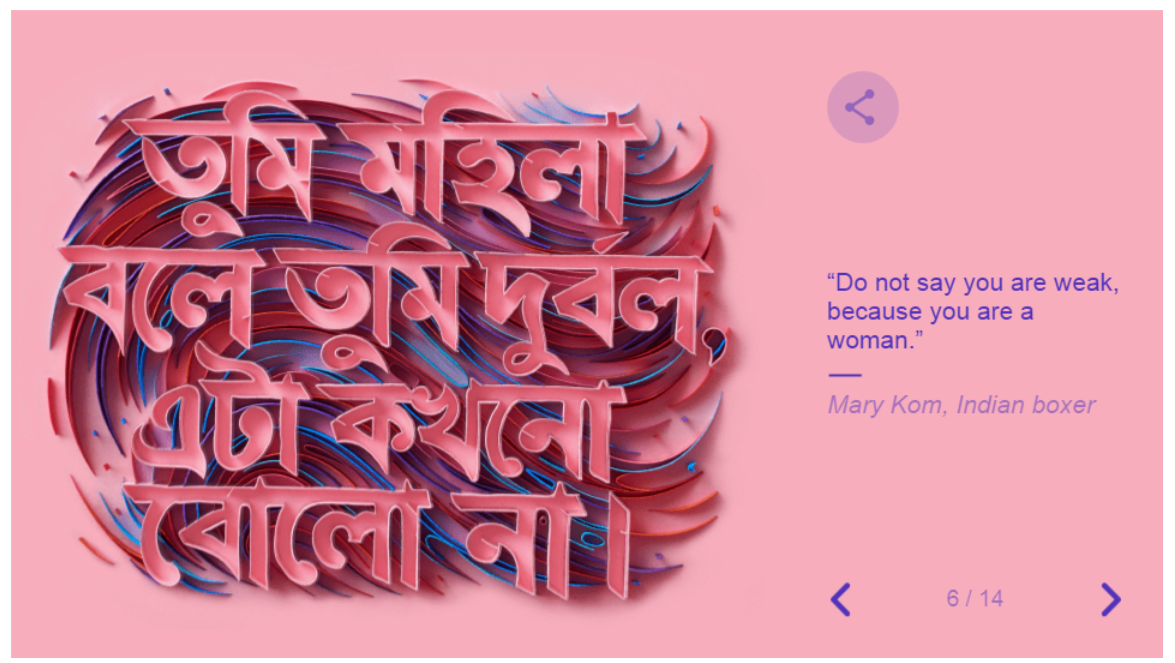
And then moves into a slideshow with quotes from famous women:
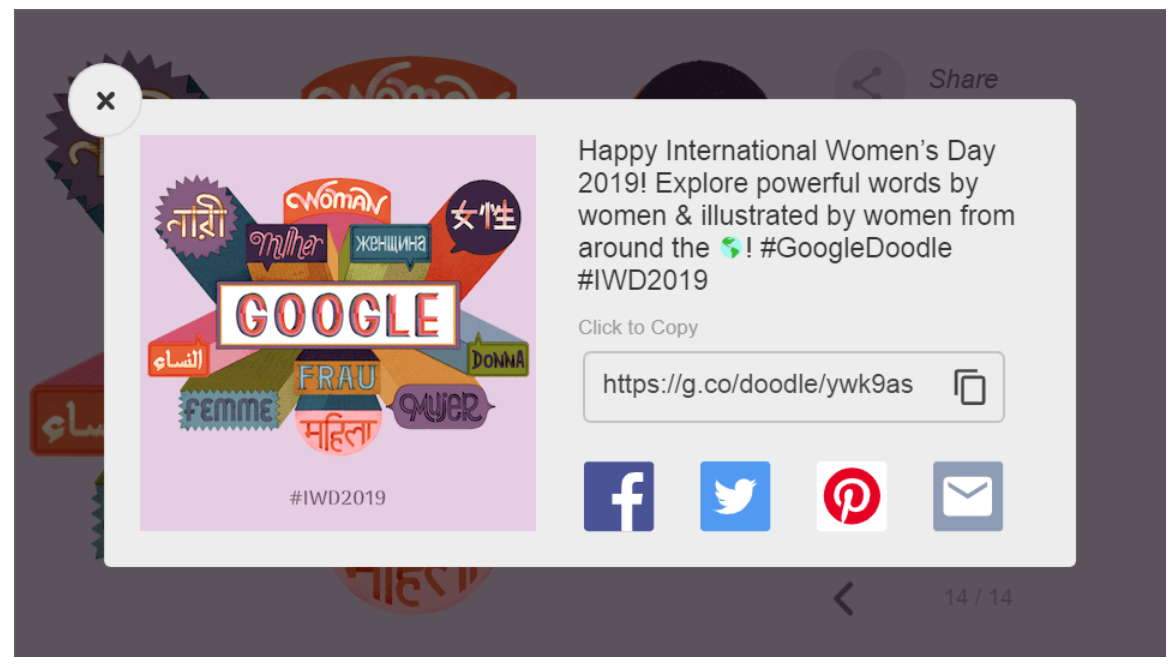
Clicking on the search option goes to a Google search for International Women’s Day. Clicking the share option goes to a screen to share on Twitter, Facebook and other social media:
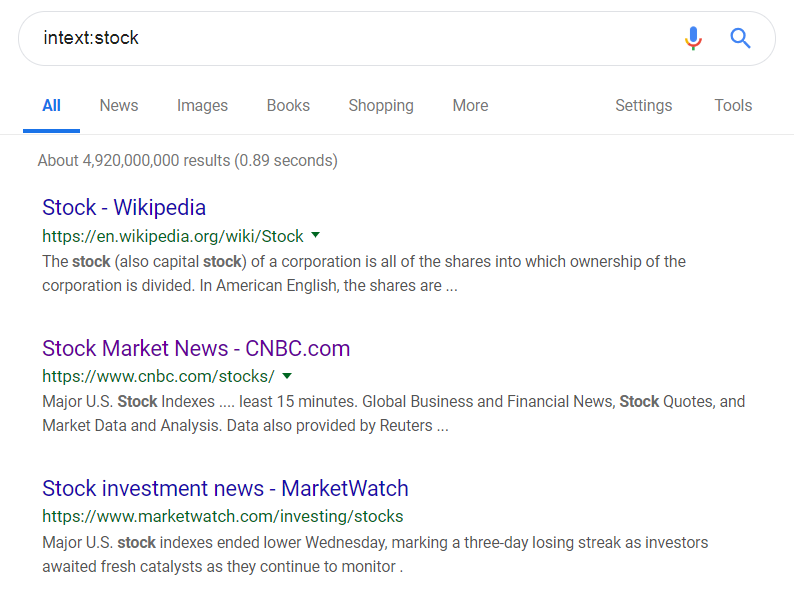
Among the less useful of operators are the intext: and allintext: search operators. As the title says, these operators require that the given word(s) show up in the content of a web page. For example, if you searched for intext:stock (no space between intext: and the searched keyword), the returned web pages would have the word stock as part of the web page:
intext:stock
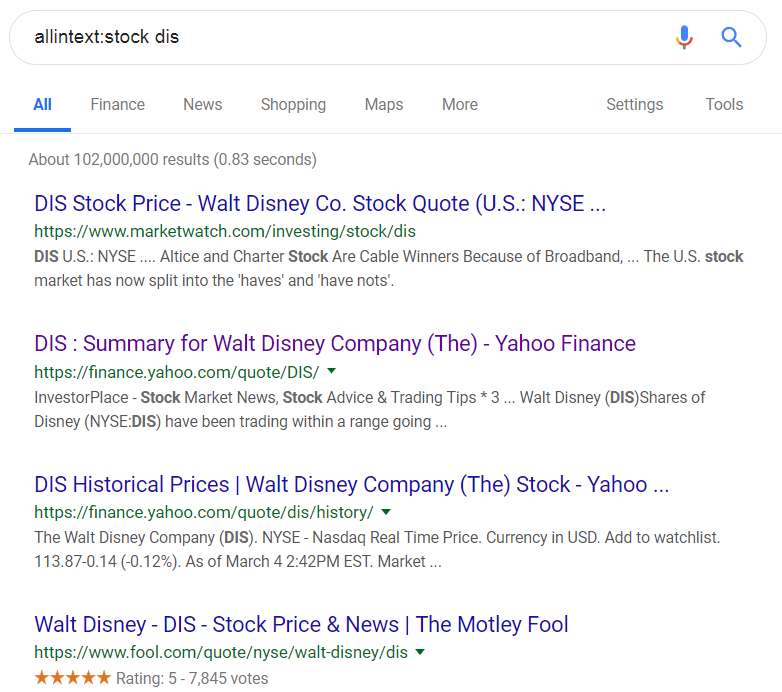
Similarly, if you searched for allintext:stock dis, you would get web pages with the words stock and dis within their text content:
allintext:stock dis
While these operators are important to remember, they’re not as useful as their intitle/allintitle/inurl/allinurl counterparts. In the vast majority of cases, skipping the intext: search function and searching on the same key words would result in the same, or largely the same, search results as using the operators.
An URL is an Uniform Resource Locator – it is the https://… gobbledegook on the top of your web browser. It’s also frequently called the web address, or just address. I will be using the words URL and address interchangeably, and you can as well.
The inurl: and allinurl: search operators search for specific words in web page URLs. These operators work best when you’re searching for product pages, or blog entries.
A good example would be to look at an Amazon product page; here’s the URL to order an Amazon gift card:
As you can see, Amazon describes the product – an Amazon gift card – in the URL itself: Amazon-Amazon-com-eGift-Cards. You’ll see this design frequently in online stores, blogs, and so forth: it helps optimize the site for search engines such as Google.
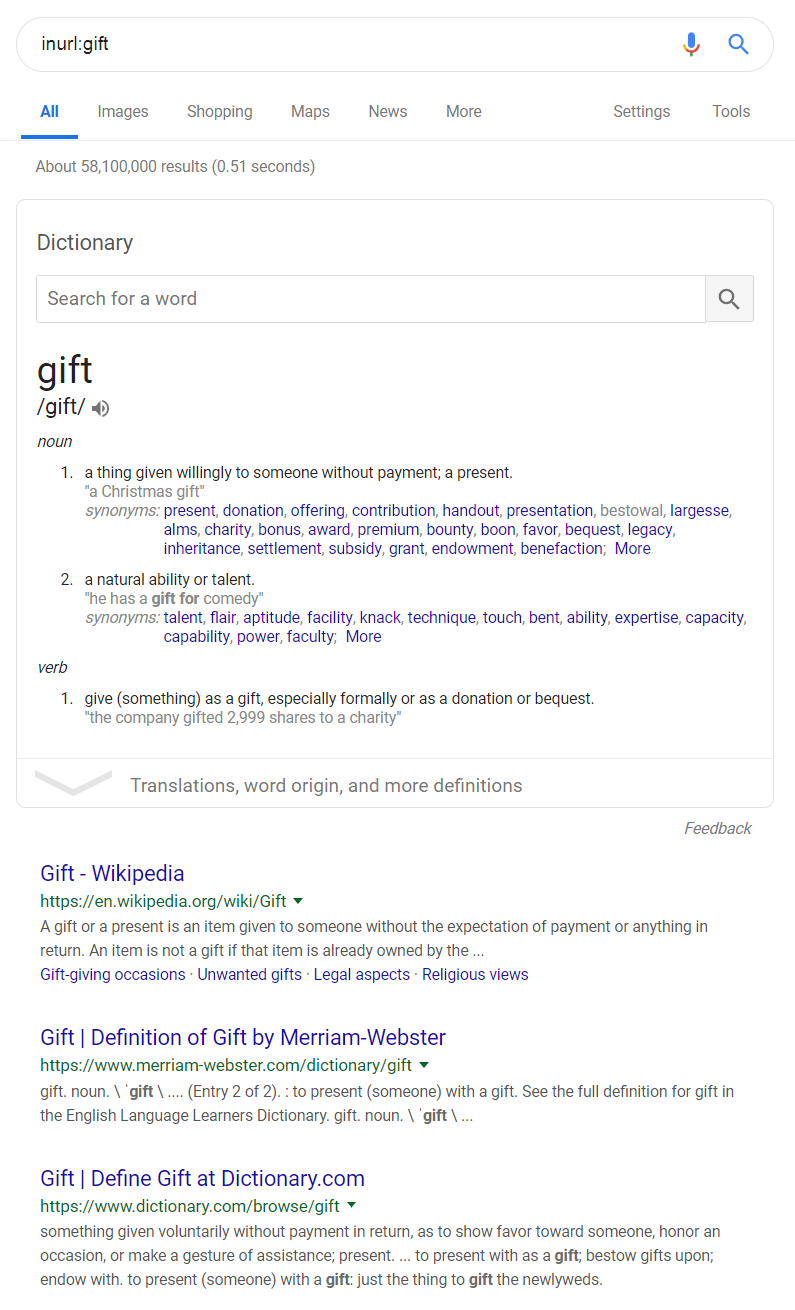
Suppose you wanted to search for gifts on Google. You might start out by searching for the following:
inurl:gift
That works – as you can see, all the URLs (green text) have the word gift in them. But the links aren’t useful: I wanted gift card information, not just general information about the word gift.
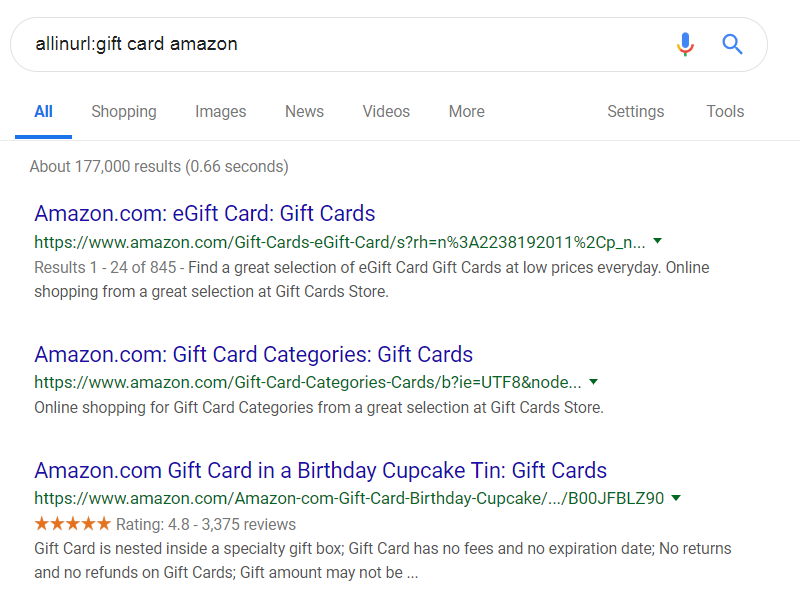
In this case, I can turn to the allinurl: operator, which will require that all the words I list should be in the URL. Let’s try:
allinurl:gift card amazon
Now that search was useful – all of these URLs (green text) contain the words amazon, gift and card.
In general, while the inurl: and allinurl: operators are incredibly useful, I would recommend trying the intitle and allintitle: operators first. Web page titles tend to be more detailed and have more space than URL addresses. inurl and allinurl are more useful for the times where you’ve forgotten a certain web page URL – the address is just on the tip of your tongue, but you can remember fragments of it – inurl and allinurl can help you reconstruct it.
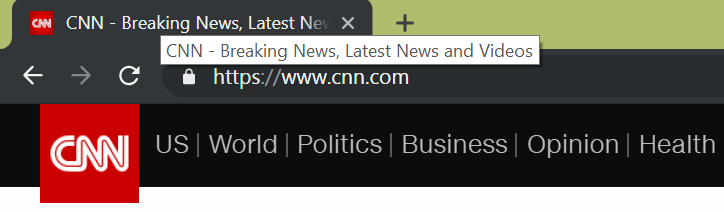
Each web page has a title – depending on your web browser, the title of a web page is shown as part of the tab or in the browser’s title bar. For example, in the picture below, the title of CNN.com is CNN – Breaking News, Latest News and Videos.
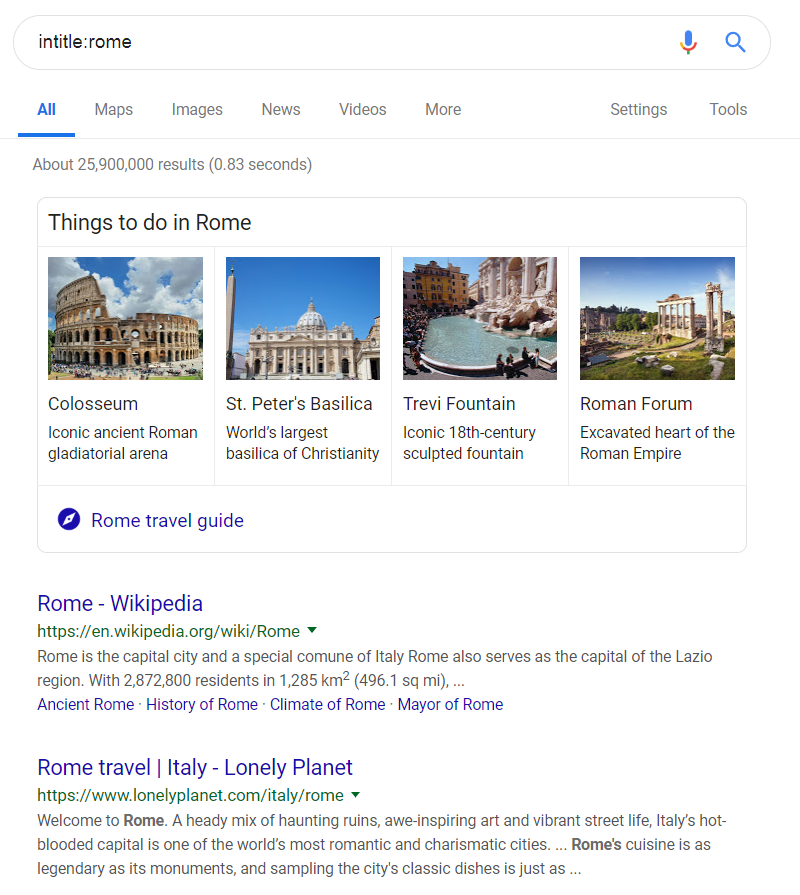
To search web pages with specific words in their titles, use the intitle: and allintitle: operator. For example, to search all web pages containing the word rome in their titles, you can search for:
intitle:rome
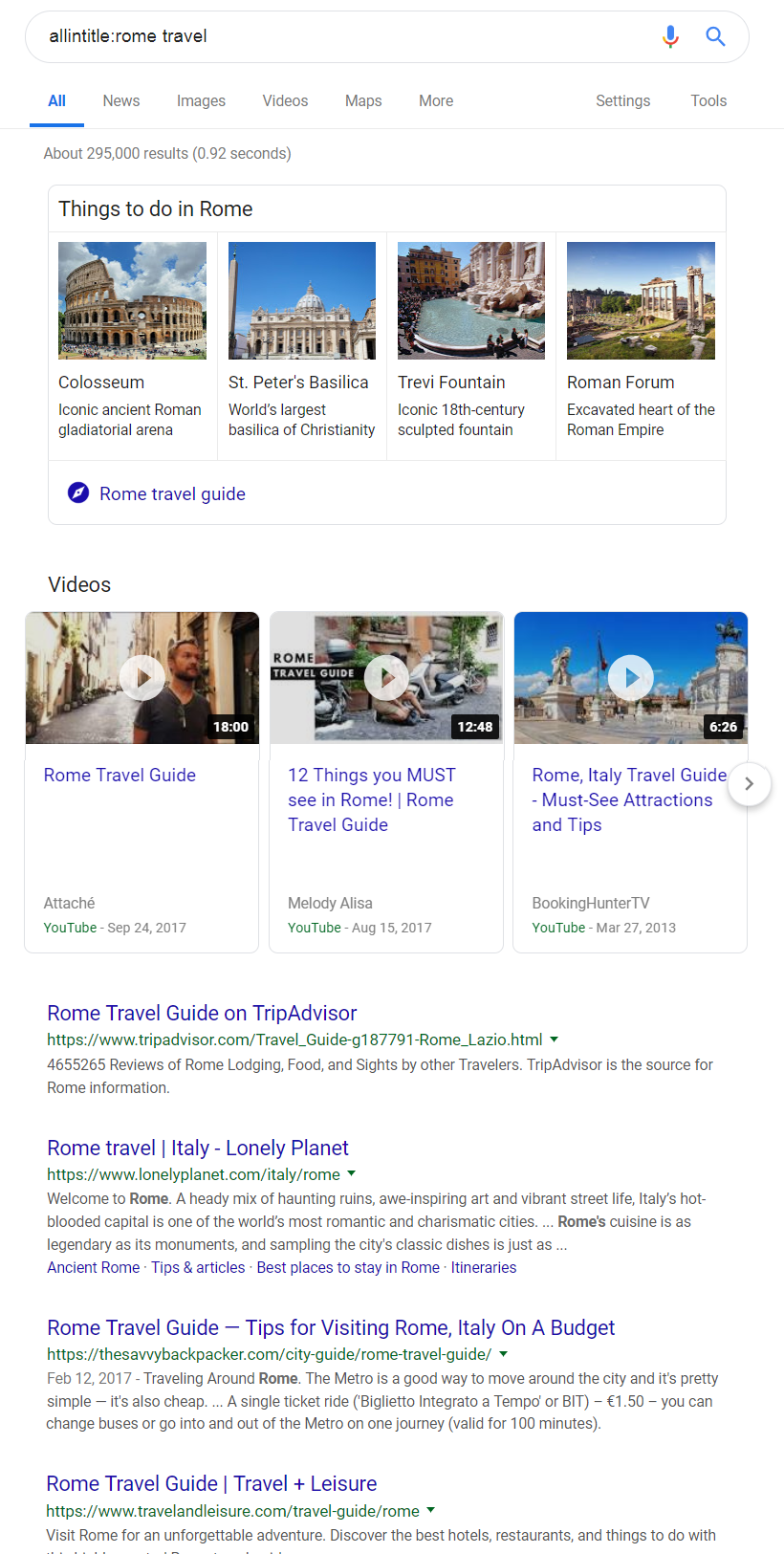
Suppose I was only interested in traveling to Rome – that entry to Wikipedia doesn’t help me figure out how to travel there. I might try the allintitle: operator, which searches for web pages containing all the words given in the title. For example:
allintitle:rome travel
The allintitle: operator works best with a few key words – remember, you’re searching web page titles which are usually short and to the point.
As Google indexes the Internet, it can make connections between related websites and content. Take advantage of these connections by using the related: operator.
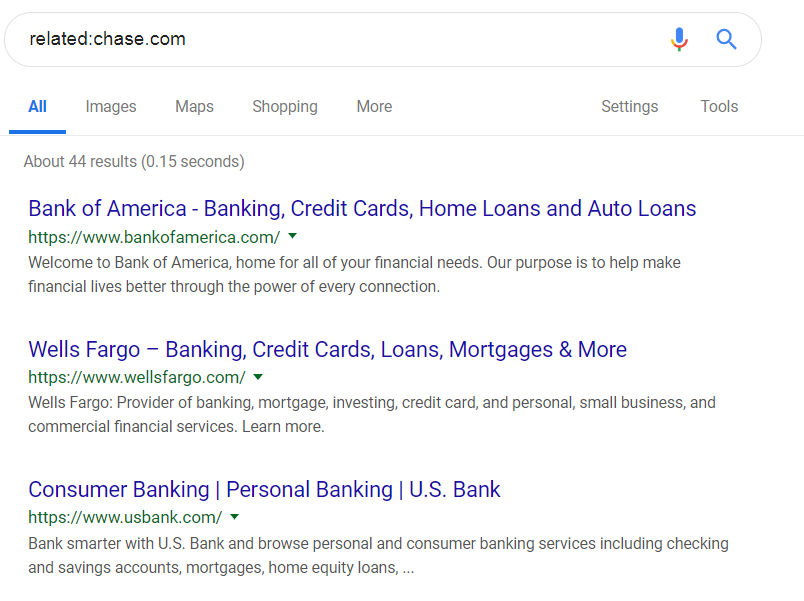
The related: operator shows related web sites. For example, if I search for related:chase.com, I’ll get a list of banks:
related:chase.com
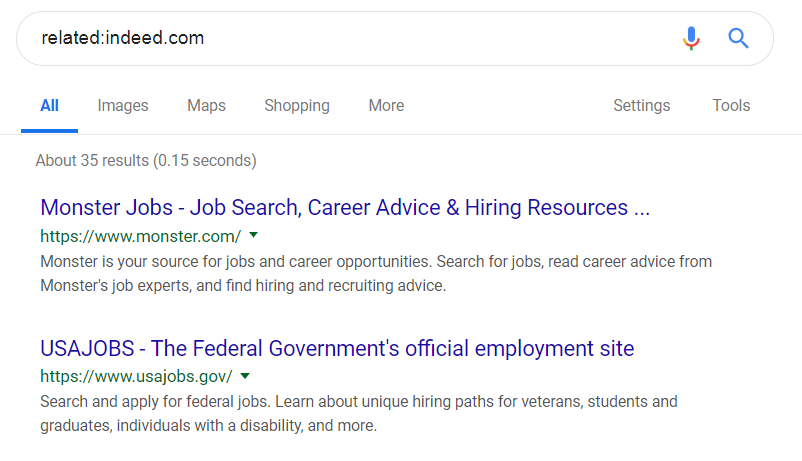
This tool is useful when you’re trying to find competitor services. For example, if I was looking for a job, I would be looking for job sites to search postings and add my resume. I know that indeed.com is one job board. I can find other job sites by using the related: operator:
Today’s Google Doodle celebrates Desi Arnaz, best known as playing Ricky Ricardo in the TV show I Love Lucy. Here’s how the Google page looked like with the doodle:
The doodle itself:
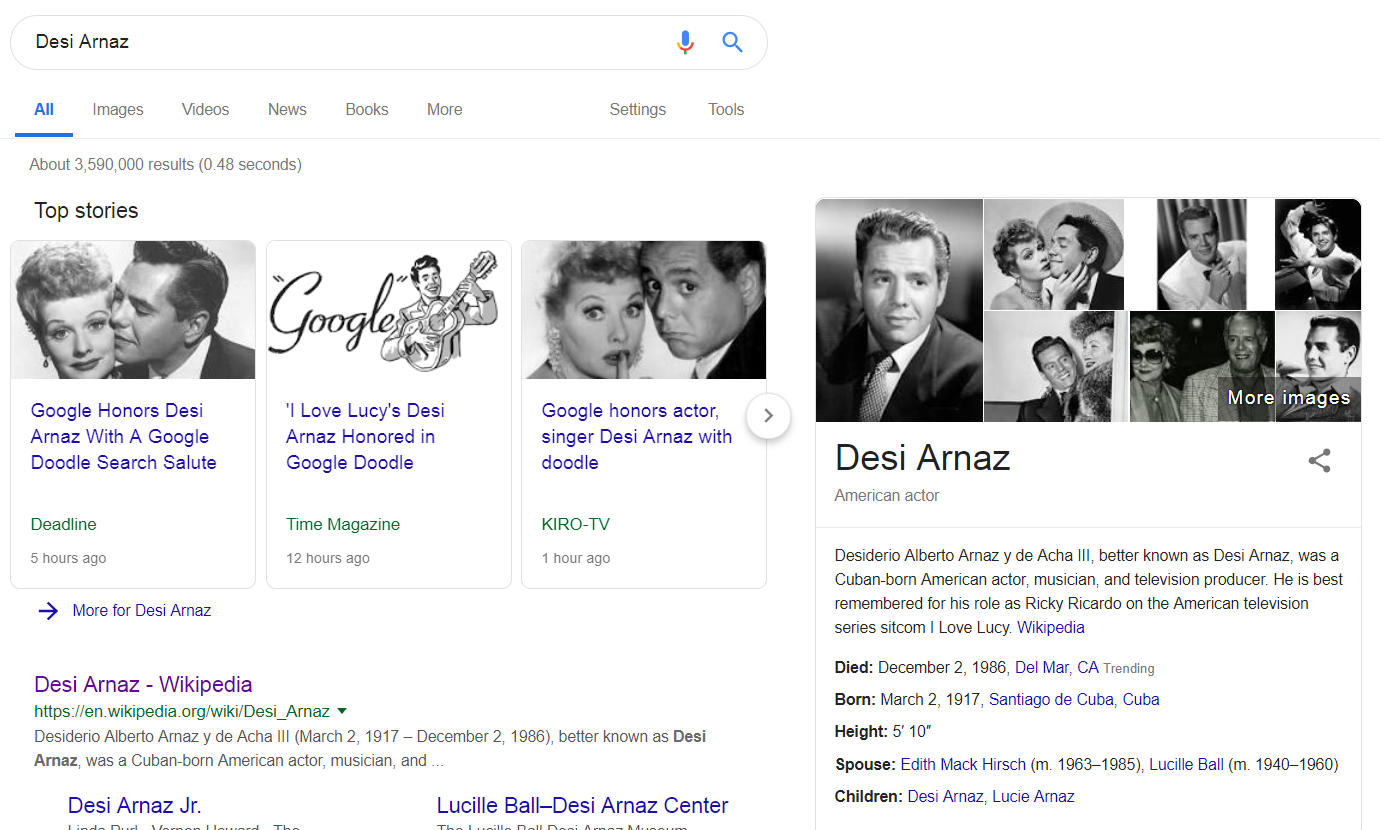
Clicking on the doodle links you to a search for Desi Arnaz:
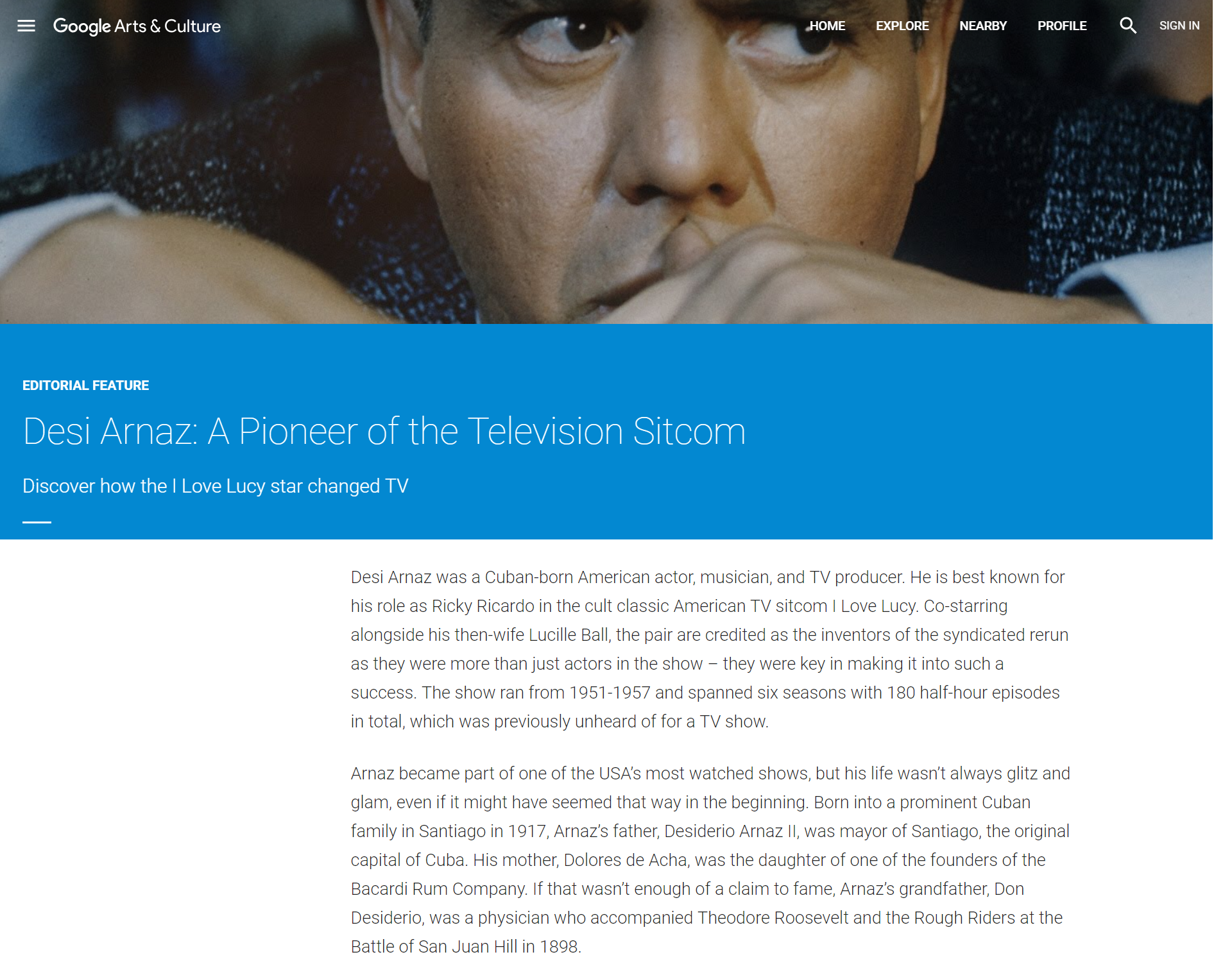
Clicking on the link to explore the life of Desi Arnaz brings you to a Google Arts & Culture article:
Here’s a short code example in Python to iterate through a folder’s ( thisisafolder ) contents within Google Cloud Storage (GCS). Each filename can be accessed through blobi.name – in the below code sample, we print it out and test whether it ends with .json.
Remember that folders don’t actually exist on GCS, but a folder-like structure can be created by prefixing filenames with the folder name and the forward slash character ( / ).
client = storage.Client()
bucket = client.get_bucket("example-bucket-name")
blob_iterator = bucket.list_blobs(prefix="thisisafolder",client=client)
#iterate through and print out blob filenames
for blobi in blob_iterator:
print(blobi.name)
if blobi.name.endswith(".json"):
#do something with blob that ends with ".json"
Sometimes, a researcher needs to find something else other than a web page. News releases and raw data are often published for release as PDF files. Microsoft Powerpoint files (.PPTX) are often used to outline new company initiatives. Microsoft Word files (.DOCX) are shared while text is being edited/approved/discussed.
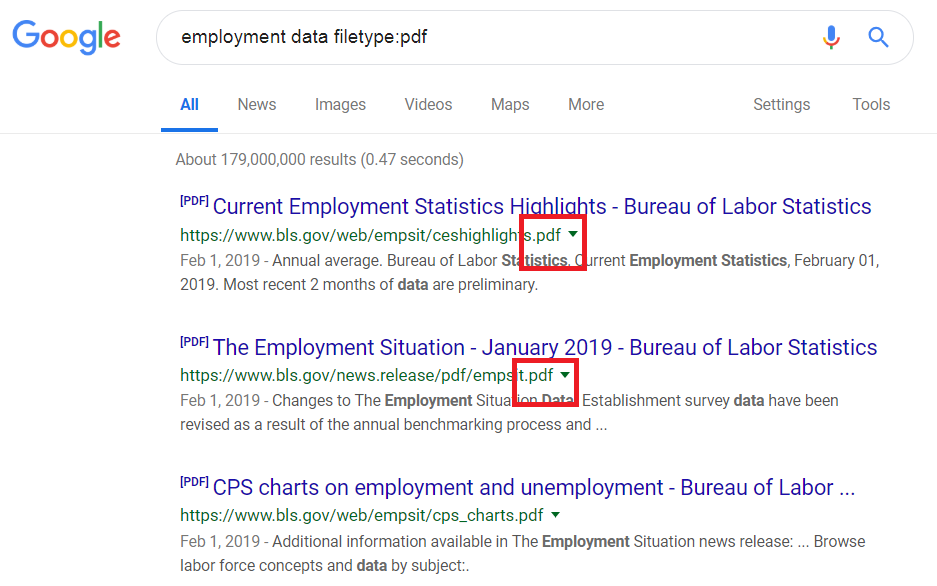
To find these files, the filetype: operator (or its alias, the ext: operator) can be used. For example, if I need to find official releases of employment data, a possible search would be one of the below:
employment data filetype:pdf
employment data ext:pdf
As you can note from the red boxes above, all the results are of .PDF files – as the search query asked for.
Google search is not just a great search engine, but also a great library of utility functions. An example of this is the define: operator.
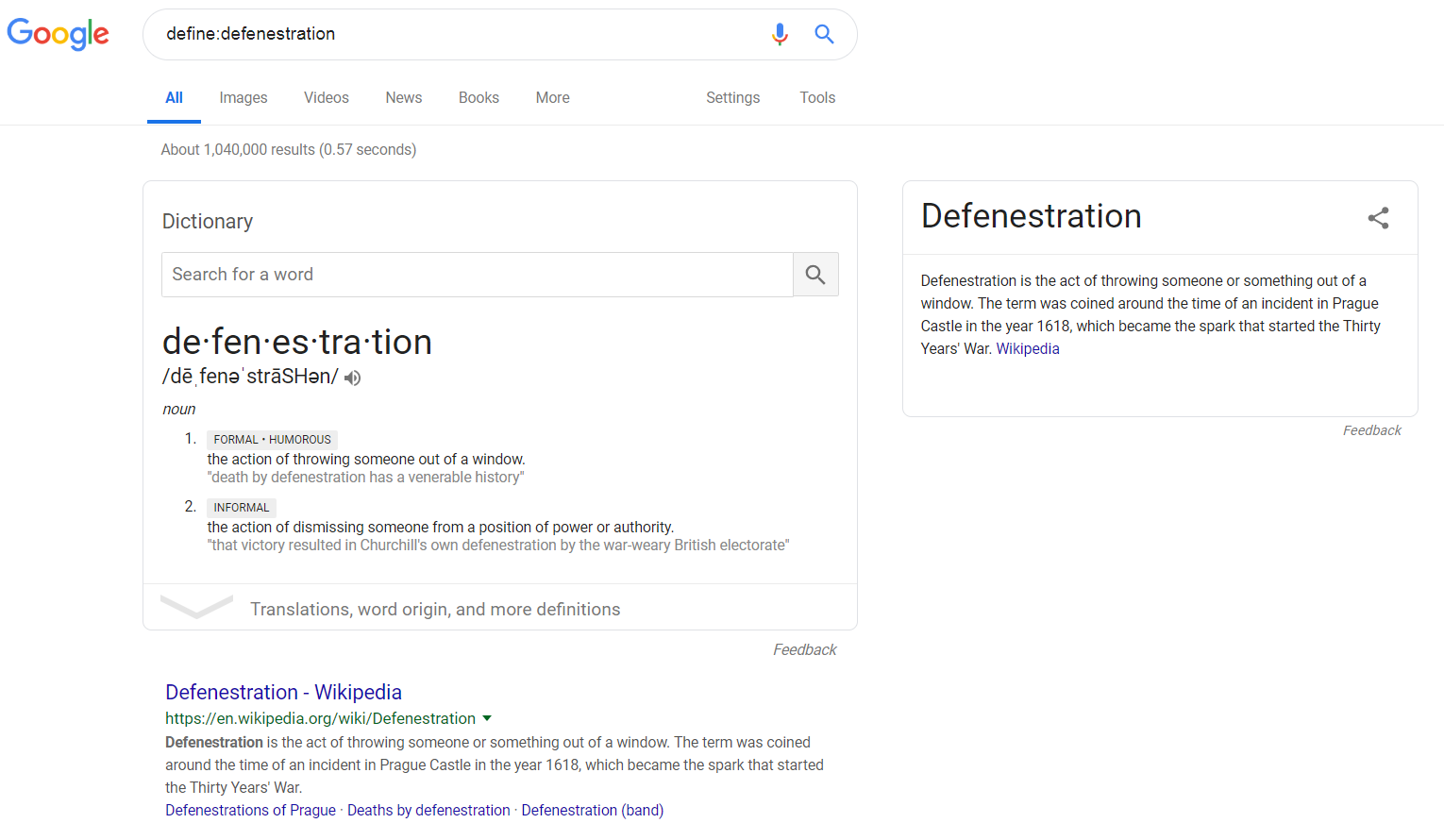
The define: operator acts as a dictionary: it lets you ask for the definition of a word. For example, searching for the below text gives me the definition of this strange word:
define:defenestration
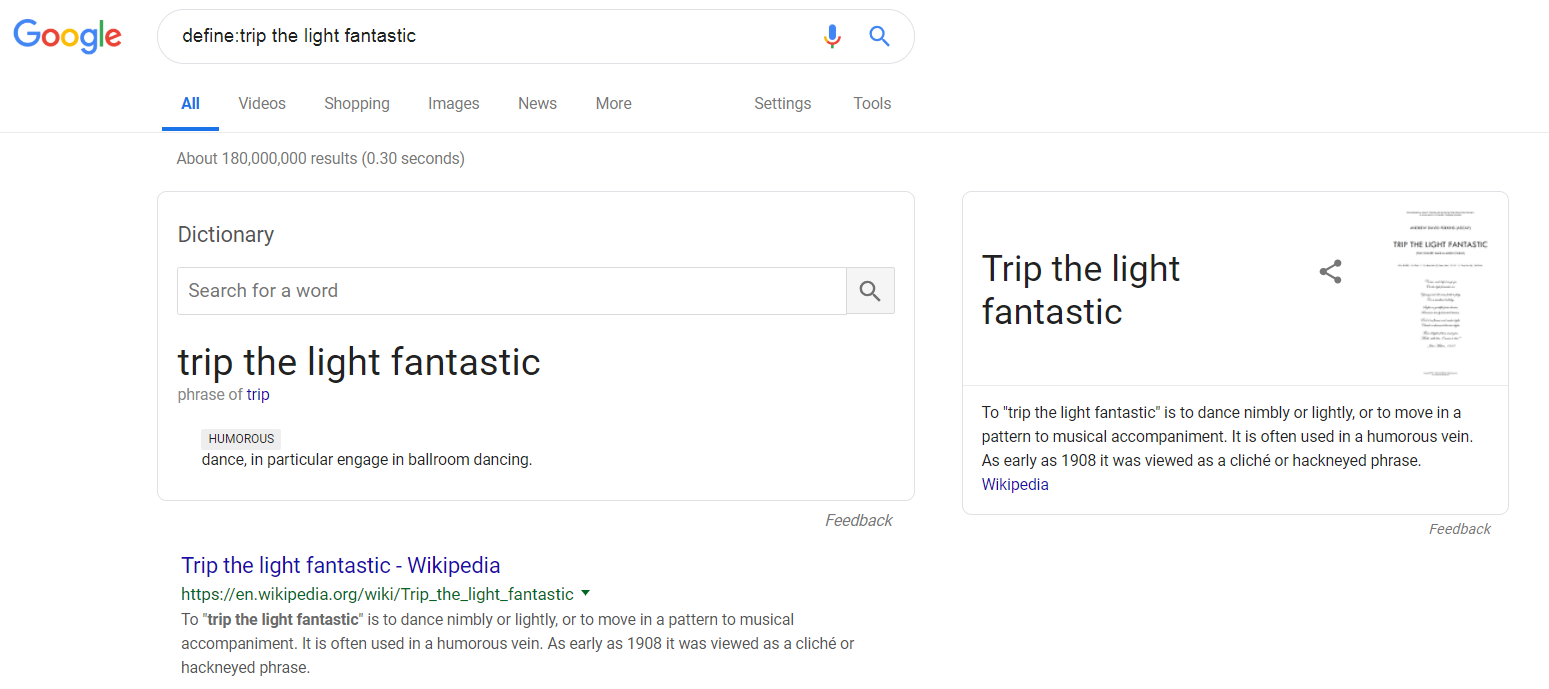
If you have a phrase you need to look up, feel free to throw it in as well. I wonder what this phrase means…
define:trip the light fantastic
I often use this function to look up domain-specific words, such as words used only in the legal or technology fields, and I’ve always found useful, intelligent definitions.