I’ve remarked before about how I love Newsblur as a replacement for Google Reader. But Newsblur can also watch for new YouTube videos via YouTube RSS feeds!
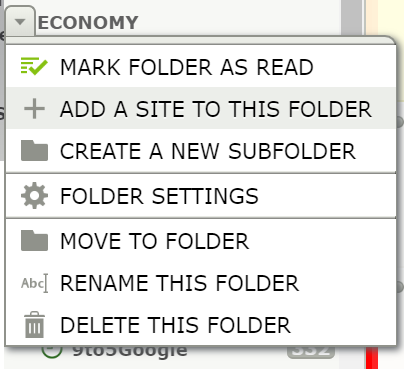
RSS support is not always clearly advertised on YouTube, but it’s simple to access. In NewsBlur, right click a folder and select Add A Site To This Folder:
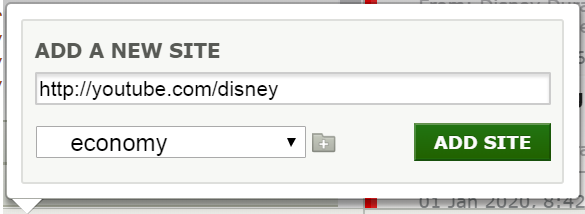
Then just insert the YouTube channel URL, and NewsBlur should load the newest YouTube videos!
This is a quick and easy way for me to monitor a lot of YouTube channels at once.
After Google Reader was shut down, I moved to NewsBlur to follow my RSS feeds. The great thing about NewsBlur is that you can add RSS feeds to a folder and Newsblur will merge all the stories under that folder into a single RSS feed.
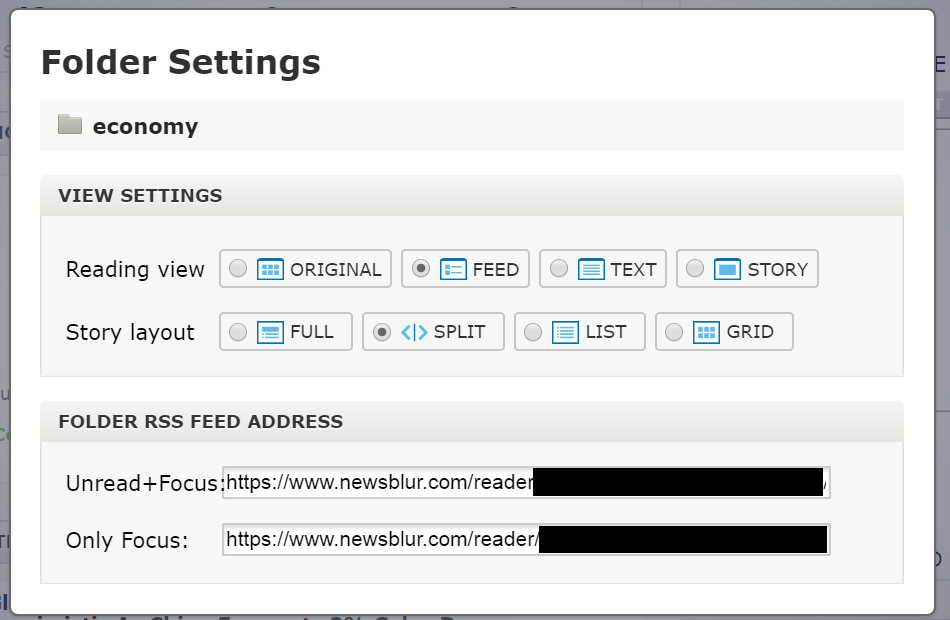
Under NewsBlur, you’ll want to pull the folder RSS feed from the settings option:
The following Python code can pull the feed and iterate through it to find article information. At the bottom of this code example, each child represents a possible article, and sub_child represents a property on the article: the URL, the title, etc. I use a variant of this code to help identify important news stories.
import requests
import xml.etree.ElementTree as ET
import logging
import datetime, pytz
import json
import urllib.parse
#tears through the newsblur folder xml searching for <entry> items
def parse_newsblur_xml():
r = requests.get('NEWSBLUR_FOLDER_RSS')
if r.status_code != 200:
print("ERROR: Unable to retrieve address ")
return "error"
xml = r.text
xml_root = ET.fromstring(xml)
#we search for <entry> tags because each entry tag stores a single article from a RSS feed
for child in xml_root:
if not child.tag.endswith("entry"):
continue
#if we are down here, the tag is an entry tag and we need to parse out info
#Grind through the children of the <entry> tag
for sub_child in child:
if sub_child.tag.endswith("category"): #article categories
#call sub_child.get('term') to get categories of this article
elif sub_child.tag.endswith("title"): #article title
#call sub_child.text to get article title
elif sub_child.tag.endswith("summary"): #article summary
#call sub_child.text to get article summary
elif sub_child.tag.endswith("link"):
#call sub_child.get('href') to get article URL
I love these types of articles – finding unexpected uses of technology to connect closer with family and friends. What I think really sells this application of Google Maps is that these are pictures of people in the middle of their everyday lives – they’re not posed, or idealized.
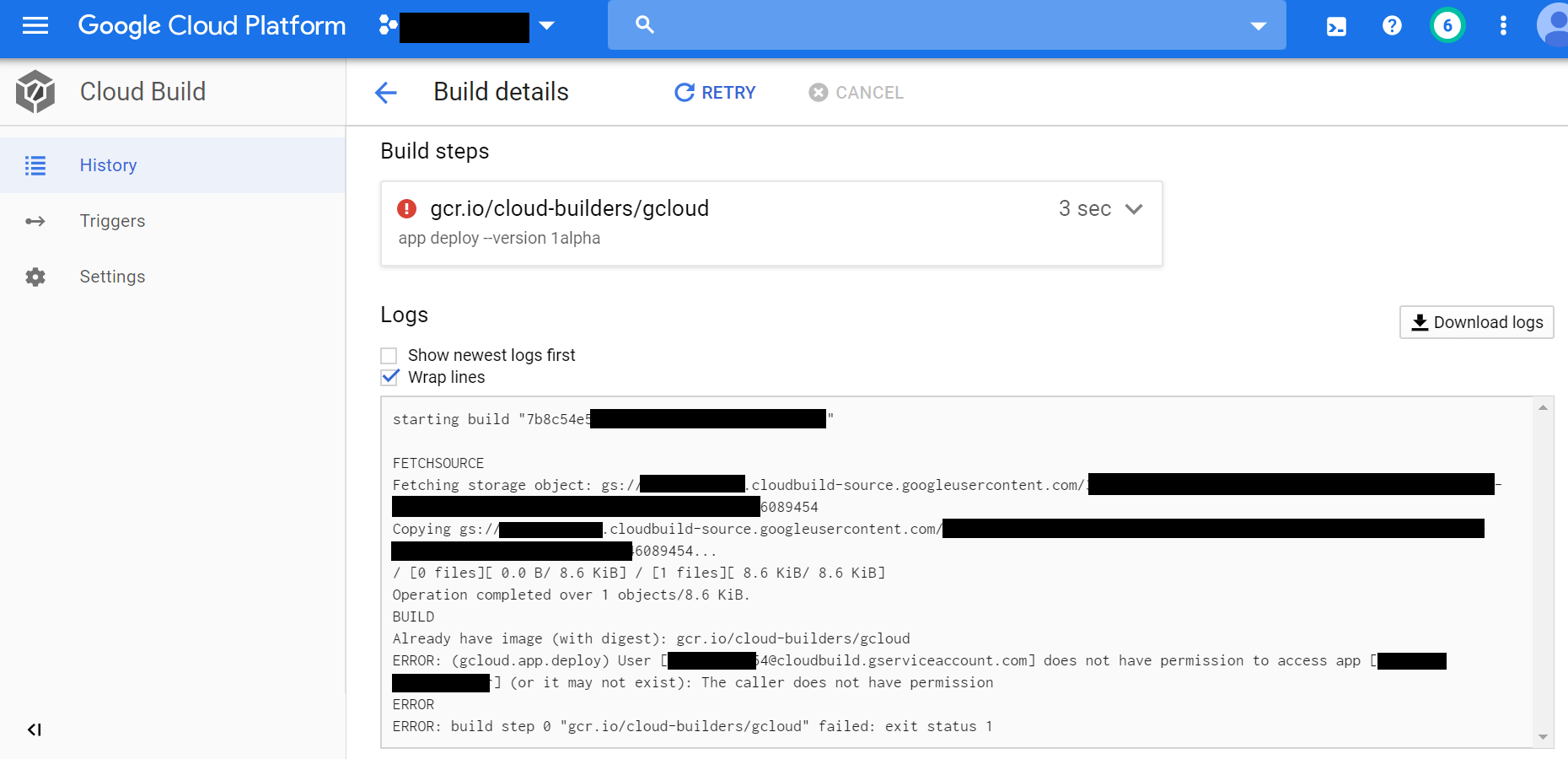
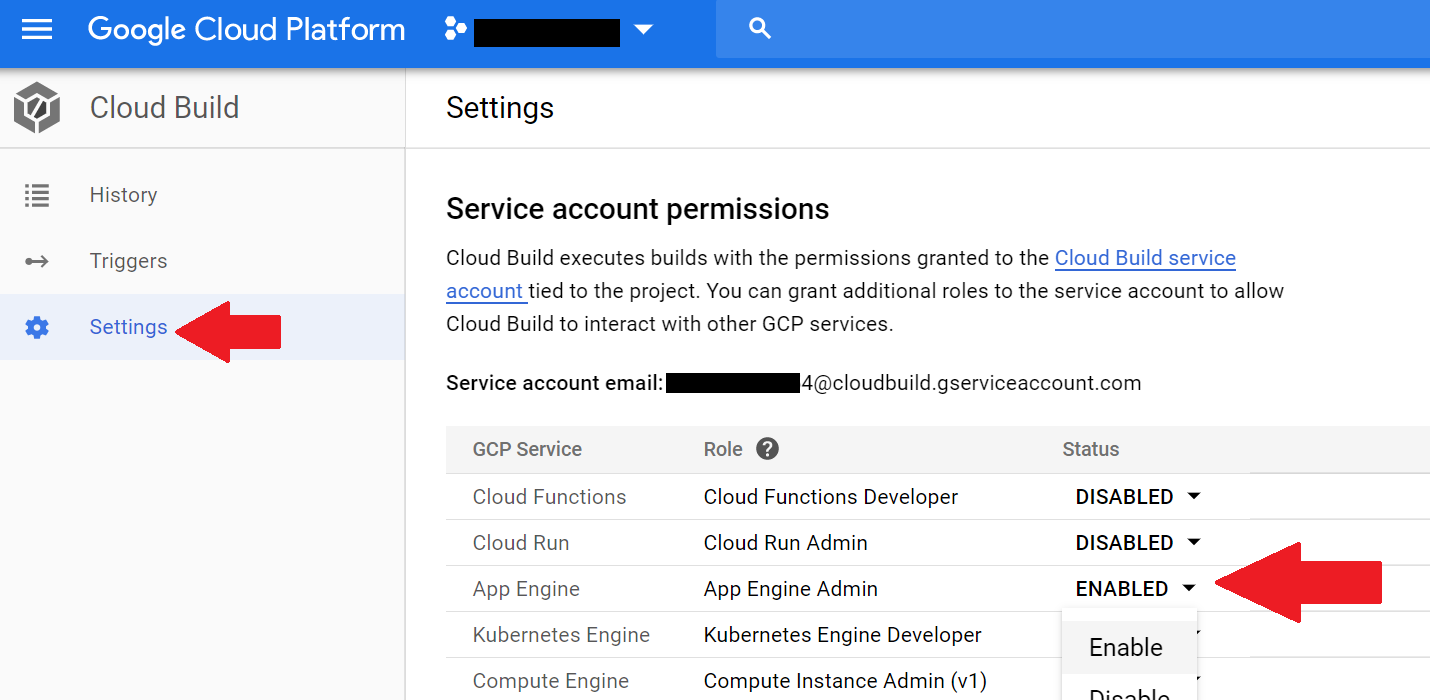
Whenever I provision a new Google Cloud project, I always get bitten by this error. I keep forgetting to set up IAM rules to allow Cloud Build access to App Engine.
Screenshot of failed Cloud Build run. Cloud Build does not have permission to access my App Engine instance.
Operation completed over 1 objects/8.6 KiB.
BUILD
Already have image (with digest): gcr.io/cloud-builders/gcloud
ERROR: (gcloud.app.deploy) User [[email protected]] does not have permission to access app [APP_ID_REDACTED] (or it may not exist): The caller does not have permission
ERROR
ERROR: build step 0 "gcr.io/cloud-builders/gcloud" failed: exit status 1
To fix this, go into Settings under Cloud Build and enable access to App Engine, and any other cloud service you use in conjunction with Cloud Build. Then wait a moment for the settings to take effect and rerun the build.
It’s important to do well in school, and having a high undergraduate GPA helps immensely if one decides to go on to graduate school, get a MBA, etc. But an internship or two on a resume helps dramatically in getting that first job – they count as experience, which means you can immediately apply for those jobs that ask for 1 – 3 years of experience. Internships also give you something to talk about during interviews – how you handled difficult situations, how you handle meetings, and all those personality-style questions.
IMO the biggest value of an internship is to understand the corporate environment: learn how to dress, how to interact with colleagues and superiors, and to be able to compare yourself talent-wise and see where you need improvement.
If you’re a Chicago area undergrad looking for an internship, I strongly recommend applying to CME Group and Chase – they pay and treat their interns very well.
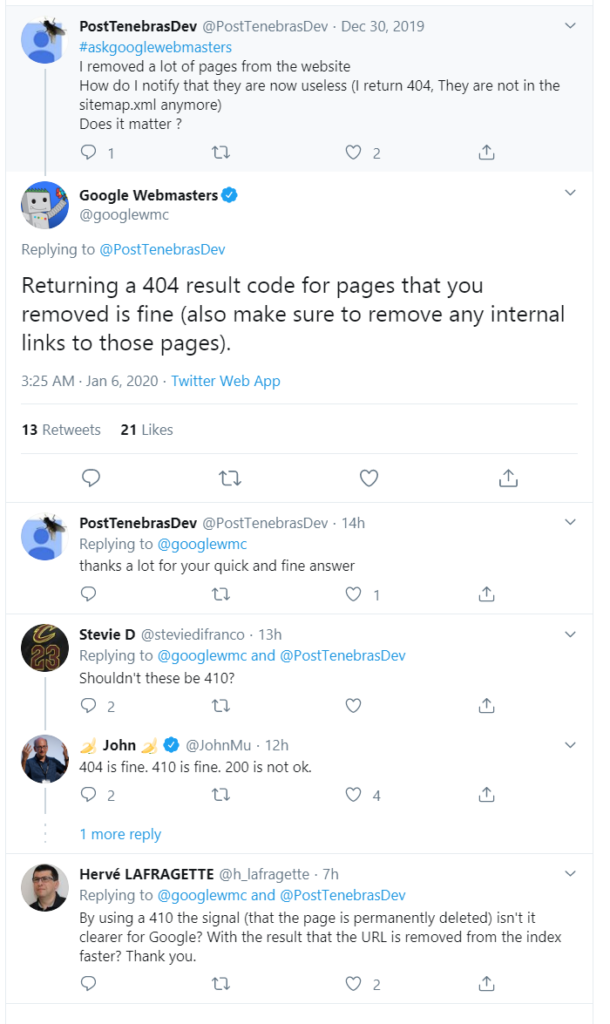
In short: if you remove a web page, make sure your server is returning 404 to correctly indicate that the page is removed and the URL is invalid.
I see a lot of sites that – for invalid URLs – return a 200 status then an error message in the body of the response. That only serves to confuse crawlers (and there are more crawlers on the web than Google’s).