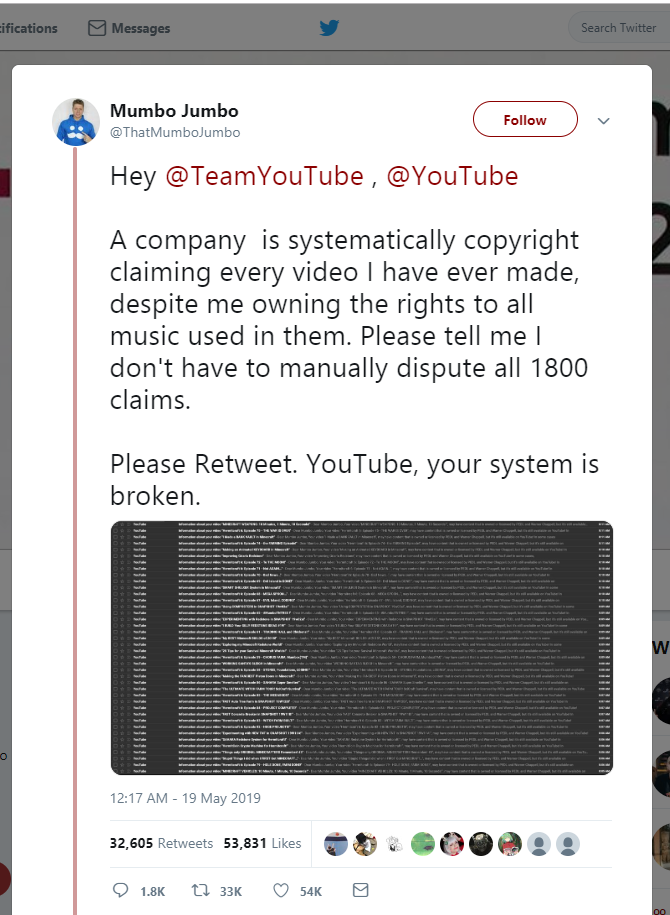
A minor scandal popped up this morning and has been making the rounds of YouTube’s gaming section. YouTube user Mumbo Jumbo, famous for his Minecraft videos, suddenly had hundreds of his videos claimed by Warner Chappell – in other words, Warner Chappell claimed that the videos used music they owned, and by claiming the videos, they earned a percentage of the profit the videos generated.
Mumbo Jumbo announced his issue on Twitter this morning:
https://twitter.com/ThatMumboJumbo/status/1130009515766755328 .
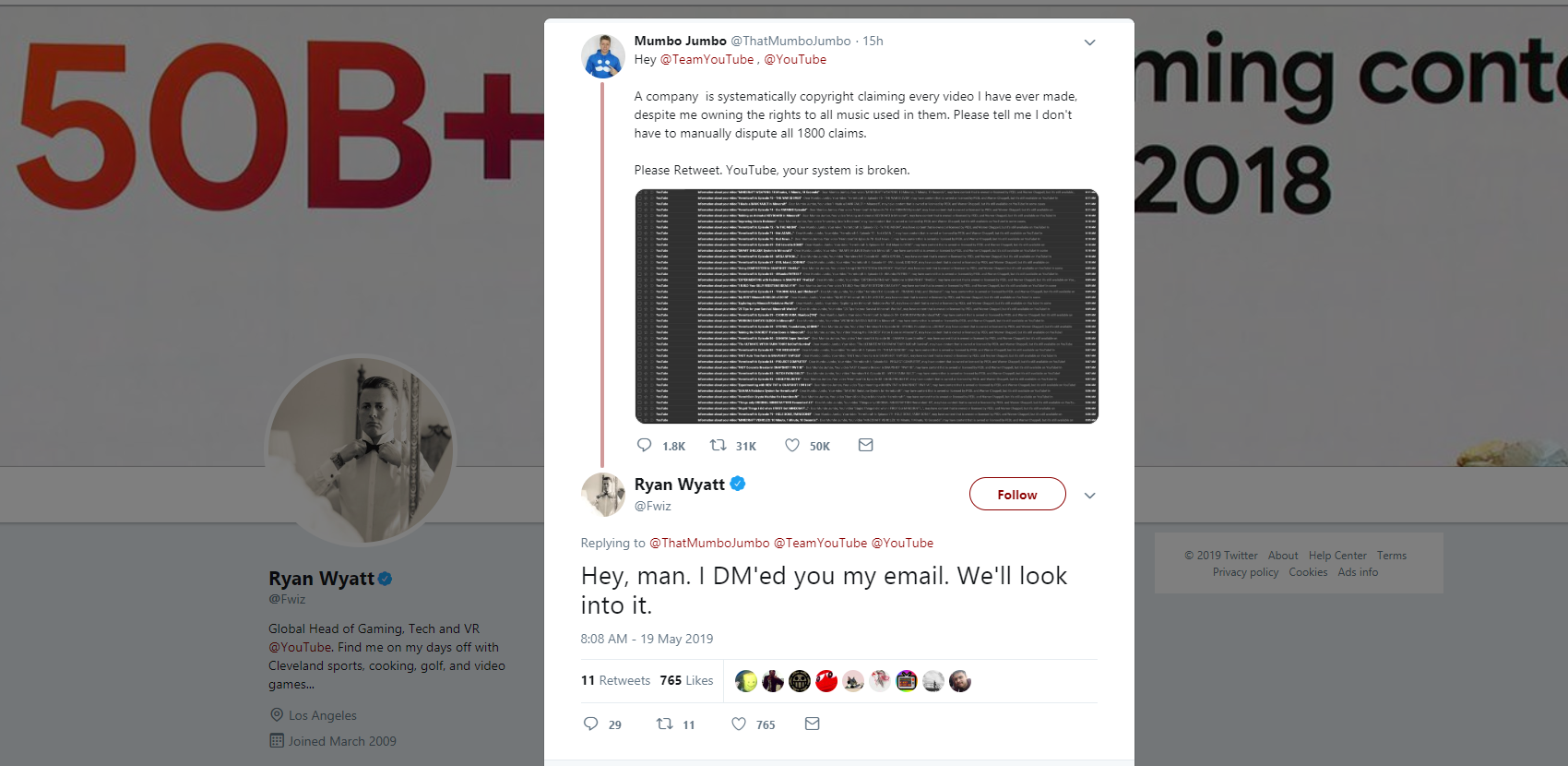
Twitter user Fwiz, the head of YouTube Gaming, replied that he was looking into it:
https://twitter.com/Fwiz/status/1130128085347516417 .
A lot of news media outlets are picking this story up such as HN: https://news.ycombinator.com/item?id=19953532 and I expect we’ll see a lot more news when business opens on Monday.